


Schlechte Datenqualität kann einen erheblichen Anteil der Einnahmen verbrauchen. IBM berichtet, dass schlechte Datenqualität die U.S.-Wirtschaft 3,1 Billionen Dollar pro Jahr kostet (IBM-Schätzung für die Kosten schlechter Daten). Für einen Marketing-Direktor ist das kein abstraktes Daten-Governance-Problem. Es zeigt sich in bezahlten Medien, die an ungültige Kontakte gesendet werden, in Vertriebszeit, die für schlechte Leads verschwendet wird, schwächerer Segmentierung und in Attributionsberichten, die gesunde Kampagnen fehlerhaft aussehen lassen.
Ich habe das gleiche Muster in Demand-Generation-Teams beobachtet. Eine Liste kann groß genug aussehen, um Pipeline-Ziele zu erreichen, während sie doppelte Datensätze, veraltete E-Mails und Formatierungsfehler verbirgt, die Antwortquoten senken und Akquisitionskosten erhöhen. E-Mail ist normalerweise der schnellste Ort, um den Verlust zu sehen, weshalb saubere E-Mail-Listen für Kampagnenleistung und Absenderruf entscheidend sind.
Die Geschäftsfrage ist einfach. Wie viel kostet es, schlechte Datensätze für ein weiteres Quartal im System zu belassen?
Diese Kosten fallen an zwei Stellen an. Erstens: direkte Verschwendung – zusätzliche Sends, höhere Plattformkosten, niedrigere Konvertierung von falsch ausgerichteten Kampagnen und SDR-Stunden, die für die Bearbeitung von Datensätzen aufgewendet werden, die nie ins System hätten eintreten dürfen. Zweitens: nachgelagerte Schäden für die Entscheidungsfindung. Wenn Lead-Quellen, firmografische Felder oder Engagement-Historie falsch sind, finanziert das Team die falschen Kanäle und streicht die richtigen. Deshalb beginnen starke Datenprogramme mit Geschäftsauswirkungen, nicht mit Datenbankperfektionismus – ein Punkt, der durch Orbit AI Datenqualitätseinblicke unterstrichen wird.
Datenbereinigung verdient Budget, wenn Teams sie als Umsatzschutz mit messbarer ROI behandeln, nicht als Routinewartung.
Datenbereinigung ist eine Umsatzstrategie, nicht eine IT-Aufgabe
Viele Organisationen sprechen immer noch von Datenbereinigung, als wäre es Verwaltungsarbeit. Das ist ein Fehler. Wenn Umsatzteams an ungültige Kontakte senden, aus fehlerhaften Datensätzen personalisieren oder nach veralteten Feldern segmentieren, haben sie es nicht mit einer technischen Unannehmlichkeit zu tun. Sie finanzieren mangelnde Leistung.
Der Grund, warum Datenbereinigung wichtig ist, hat weniger mit gepflegten Datenbanken zu tun und mehr mit Ausführungsqualität. Marketing kann starke kreative Inhalte, intelligente Angebote und disziplinierte Kampagnenplanung erstellen und dann an Leistung verlieren, weil die Zielgruppendatei zum Zeitpunkt des Versands falsch ist. Vertrieb kann ein vielversprechendes Gebiet bearbeiten und dann feststellen, dass das CRM voller Duplikate, veralteter Rollen und ungültiger E-Mail-Adressen ist. Produktteams können das Anmeldeverhalten untersuchen und dann Entscheidungen auf der Grundlage fehlerhafter Eingaben treffen.
Ein großer Teil des stärksten operativen Denkens in diesem Bereich behandelt Datenhygiene jetzt als Geschäftssystem, nicht als einmalige Bereinigung. Die Perspektive in Orbit AI Datenqualitätseinblicke ist nützlich, weil sie Datenqualität mit betrieblicher Zuverlässigkeit verbindet, anstatt sie als isolierte Datenbankaufgabe zu behandeln.
Praktische Regel: Wenn ein Feld Targeting, Personalisierung, Routing oder Berichterstattung beeinflusst, ist es kein IT-Feld. Es ist ein Umsatzfeld.
Dieser Perspektivwechsel ist wichtig, weil schlechte Kontaktdaten dazu neigen, sich hinter Kanal-Metriken zu verstecken. Teams machen Betreffzeilen, Angebotsqualität oder Geschwindigkeit der Nachverfolgung verantwortlich, wenn die Liste selbst das Problem ist. Bei E-Mail-Programmen bestimmt die Listenqualität besonders, ob die Kampagne überhaupt eine faire Chance hat. Deshalb beginnen viele Teams damit, die Listenhygiene zu verschärfen und Ressourcen wie Warum saubere E-Mail-Listen wichtig sind zu überprüfen, bevor sie ihre Strategie anderswo ändern.
Die Anatomie schlechter Daten
Schlechte Daten schaffen Betriebsrisiken, lange bevor sie als Datenbqualitätsproblem erkannt werden. In der Praxis zeigen sie sich als bezahlte Kampagne an ungültige Posteingänge gesendet, Leads an den falschen Vertreter weitergeleitet, doppelte Kontakte, die die Pipeline-Anzahl aufblähen, oder Einwilligungsdatensätze, die nicht mehr damit übereinstimmen, was Marketing versenden darf.
In CRMs, ESPs, Anmeldungsformularen, Enrichment-Tools und BI-Plattformen kündigen sich fehlerhafte Datensätze selten an. Sie sehen nutzbar aus, bis ein Team versucht, sie zu segmentieren, zu routen, zu personalisieren, zu melden oder Prognosen zu erstellen. Darum sind schlechte Daten teuer. Sie schlagen fehl zum Zeitpunkt der Verwendung, nachdem bereits Budget, Zeit und Entscheidungsfindung eingeplant wurden.
Schlechte Daten zeigen sich in fünf bekannten Formen
Dies sind die Fehlermuster, die den Großteil des Betriebswiderstands verursachen:
Unvollständige Datensätze
Fehlende Felder unterbrechen Segmentierungsregeln, Lead-Scoring, Routing-Logik und Personalisierung. Ein Kontakt ohne gültige E-Mail, Region oder Lifecycle-Stadium kann monatelang in der Datenbank sitzen und ist immer noch unbrauchbar, wenn die Kampagne live geht.Ungenaue Einträge
Tippfehler, gefälschte Eingaben, fehlerhafte Adressen und ungenaue Firmographic-Details erzeugen falsches Vertrauen. Der Datensatz existiert, aber das Team kann sich nicht darauf verlassen.Doppelte Datensätze
Duplikate teilen Engagement-Historie, Attribution und Eigentümerschaft auf. Marketing kann einen Datensatz unterdrücken und den anderen per Mail versenden. Vertrieb kann denselben Käufer zweimal anrufen. Berichte zählen dann Aktivitäten über zwei Profile und stellen die Leistung falsch dar.Inkonsistente Formatierung
Derselbe Unternehmensname, das Land oder die Berufsbezeichnung erscheinen in mehreren Formaten. Filterung wird unzuverlässig, Matching-Regeln verpassen offensichtliche Überschneidungen, und Teams beginnen, Berichte manuell in Tabellen zu reparieren.Veraltete Daten
Menschen wechseln Jobs, Abteilungen fusionieren, Posteingänge werden inaktiv und der Einwilligungsstatus ändert sich im Laufe der Zeit. Datenverschlechterung ist normal. Der Betriebsfehler besteht darin, den gestrigen gültigen Datensatz als heutigen sicheren Datensatz zu behandeln.
Für E-Mail-Teams konvergieren diese Probleme häufig in einer Liste. Eine einzelne Datei kann aufgegebene Posteingänge, Rollenkonten, Catch-All-Domänen, Duplikate und Formatierungsfehler gleichzeitig enthalten. Eine praktische Erklärung von was List-Cleaning für E-Mail-Performance beinhaltet hilft zu verdeutlichen, warum „ein paar schlechte Kontakte entfernen" zu eng gefasst ist.
Cleaning wird auch mit Collection verwechselt. Das sind unterschiedliche Aufgaben. Das Hinzufügen von mehr Datensätzen zu einem kaputten System erhöht normalerweise die Fehlermenge, weil dieselben schwachen Validierungsregeln, Feldstandards und Synchronisierungsprobleme immer wieder neue fehlerhafte Einträge produzieren.
Der Prozess selbst ist etabliert. Die technische Übersicht in der Referenz zum Datenbereinigungsworkflow beschreibt Kernschritte wie das Entfernen von Duplikaten, das Behandeln fehlender Werte, das Standardisieren von Formaten, das Validieren der Vollständigkeit und das Überprüfen der Genauigkeit vor Analyse oder Aktivierung. Diese Arbeit sitzt vorgelagert zur Berichtsqualität, Automatisierungsqualität und Modellqualität.
Das Prinzip „Garbage in, Garbage out" ist eine wörtliche Beschreibung dessen, was im Betrieb geschieht. Berichte spiegeln schlechte Eingaben wider. Automatisierungen werden unter falschen Bedingungen ausgelöst. Modelle lernen von Datensätzen, die niemals Produktionssysteme erreichen hätten sollen.
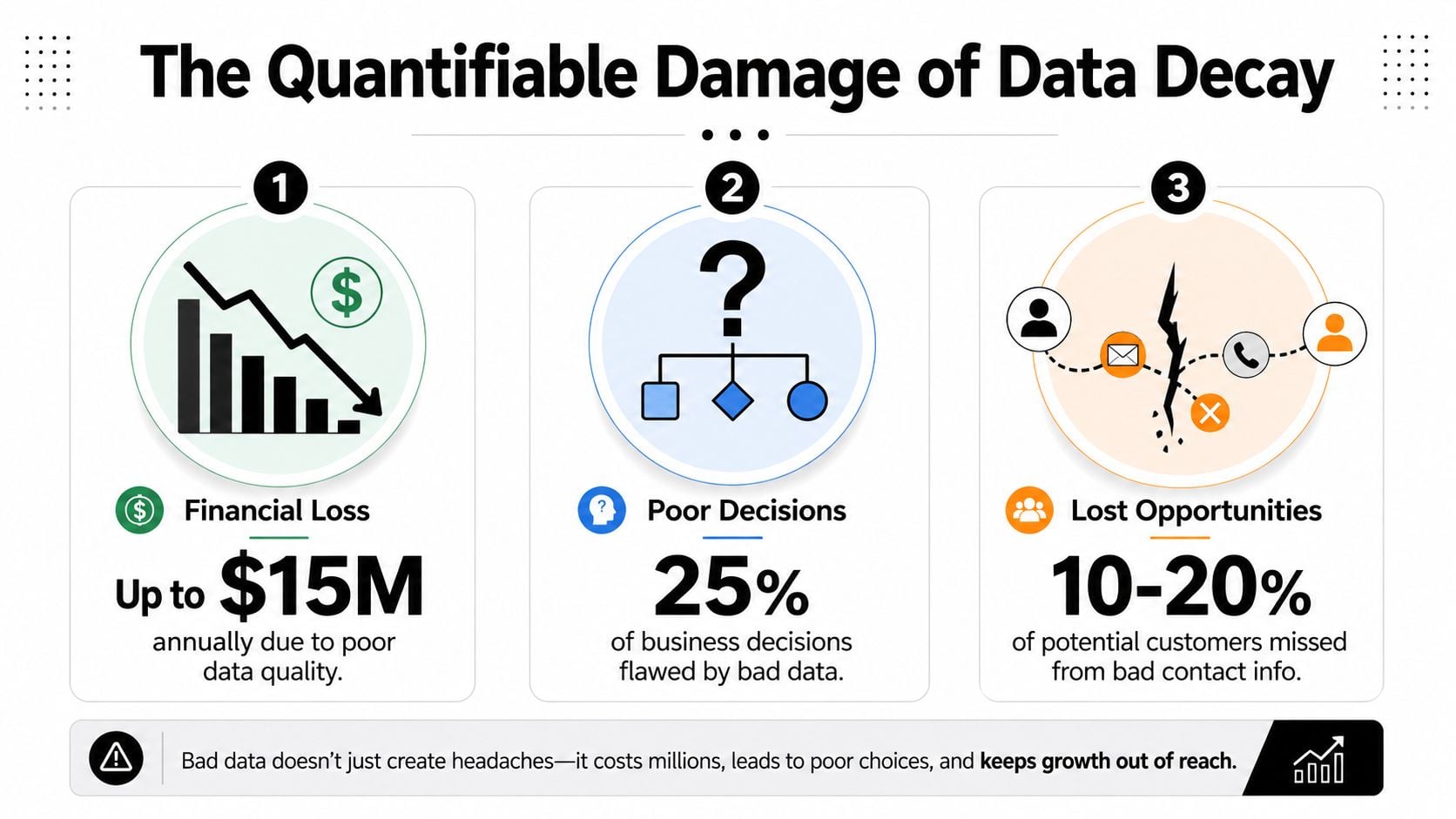
Der quantifizierbare Schaden durch Datenverschlechterung
Schlechte Datenqualität kostet Organisationen durchschnittlich 12,9 Millionen Dollar pro Jahr, laut IBM. Diese Schlagzeile zieht Aufmerksamkeit auf sich, aber der betriebliche Schaden wird leicht übersehen, da er in Dutzenden Posten auftaucht: verschwendete Mediaausgaben, niedrigere Konversionsraten, schlechte Prognosen und Kundenerlebnisse, die nachlässig statt koordiniert wirken (IBM via Experian).
Kleine Listenprobleme werden zu großen finanziellen Lecks
E-Mail macht die Kosten schnell sichtbar. Wenn 10% einer 100.000er-Kontaktliste ungültig sind und Sie trotzdem für diese Kontakte bezahlen, um sie zu erwerben oder zu kontaktieren, wird das Budget bereits verbrannt, bevor die Kampagne die Chance zu performen hat. Dann kommen die Folgekosten. Höhere Bounce-Raten beeinträchtigen die Inbox-Platzierung, was den Wert der gültigen Adressen reduziert, die Sie noch haben.
Deshalb überwachen E-Mail-Zustellbarkeit-Teams die Bounce-Rate als Gewinnmetrik, nicht nur als E-Mail-Metrik. Eine praktische Erklärung zu warum Bounce-Raten für den Kampagnenerfolg wichtig sind zeigt, wie Listenverfall zu Sendereputationsproblemen führt, die zukünftige Sends beeinflussen, nicht nur den aktuellen.
Ich habe das in vierteljährlichen Reviews beobachtet. Marketing meldet ein Kreativ- oder Angebotsproblem. Das eigentliche Problem ist die Listenqualität. Das Team optimiert weiterhin die Werbetexte, während Mailbox-Anbieter die Inbox-Platzierung reduzieren.
Die Lösung beginnt mit besseren Eingaben. Teams, die Adressen vor dem Start und zwischen Kampagnen verifizieren, können die Qualität der Marketing-Liste sicherstellen und aufhören, für den Versand von Nachrichten zu bezahlen, die nie zustellbar waren.
Schlechte Datensätze verzerren Entscheidungen nach dem Kampagnenende
Die höheren Kosten erscheinen oft nach dem Versand. Schmutzige Daten beschädigen die Attribution, Zielgruppendefinitionen und Leistungsberichte. Wenn doppelte Datensätze die Kundeninteraktionsverlauf auf zwei Profile aufteilen, kann ein Kunde wie zwei schwache Leads aussehen, anstatt ein qualifizierter Käufer zu sein. Wenn das Lebenszyklus-Stadium oder der Zustimmungsstatus veraltet ist, wird die falsche Zielgruppe in die falsche Kohorte gezählt. Das ändert Budget-Entscheidungen.
Gartner hat geschätzt, dass schlechte Datenqualität Organisationen durchschnittlich 12,9 Millionen Dollar pro Jahr kostet, und diese Zahl erklärt, warum schlechte Datensätze mehr als nur technische Aufräumarbeiten verursachen. Sie führen zu finanziellen Fehlern auf Managemententebene, da Teams Ausgaben, Kopfzahl und Kanalmix basierend auf Berichten zuordnen, denen sie nicht trauen sollten (Gartner, zitiert hier).
Das Kundenerlebnis leidet ebenfalls. Twilio Segment stellte fest, dass 56% der Verbraucher nach einer personalisierten Erfahrung zu Wiederholungskäufern werden, was bedeutet, dass ungenaue Personalisierung einen direkten Umsatzverlust mit sich bringt, wenn die zugrunde liegenden Daten falsch sind (Twilio Segment Personalisierungsbericht). Doppelte Kontakte, veraltete Voreinstellungen und falsche Bezeichner führen zu wiederholten Nachrichten, irrelevanten Empfehlungen und offensichtlichen CRM-Fehlern, die signalisieren, dass die Marke nicht aufpasst.
Hier ist das Geschäftsmuster:
| Betriebliches Problem | Unmittelbare Auswirkung | Geschäftsfolge |
|---|---|---|
| Ungültige E-Mail-Adressen | Höhere Bounces | Verschwendetes Versendbudget und niedrigere Inbox-Platzierung |
| Doppelte Kontakte | Fragmentierte Historien und wiederholte Kontaktaufnahme | Schlechtes Kundenerlebnis und unzuverlässige Attribution |
| Falsche CRM-Felder | Fehlerhafte Segmentierung | Falsch ausgerichtete Kampagnen und verlorene Konversionsgelegenheit |
| Veraltete Zustimmung oder Kundenstatus | Nachrichten an die falsche Zielgruppe | Compliance-Risiko und Markenschaden |
Ein paar schlechte Datensätze bleiben nicht klein. Sie verbreiten sich durch Berichterstattung, Automatisierung, Targeting und Kundenkontaktpunkte, bis ein Datenhygiene-Problem zu einem Umsatzproblem wird.
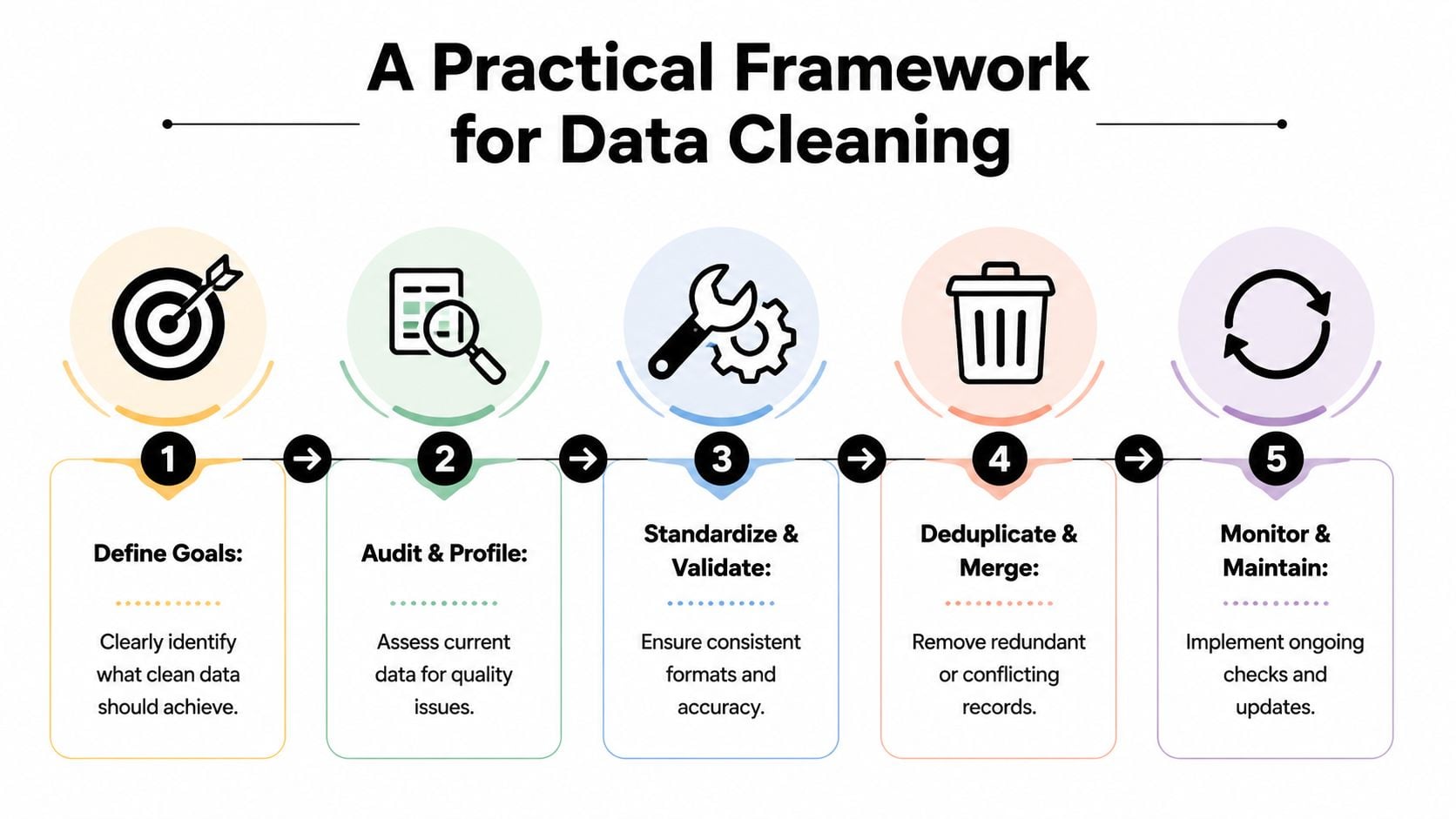
Ein praktisches Framework für Datenbereitung
Sobald Teams akzeptieren, dass Datenqualität die Einnahmen beeinflusst, besteht die nächste Herausforderung in der Priorisierung. Die meisten Datenbanken enthalten zu viele Probleme, um alles auf einmal zu bereinigen. Der richtige Schritt ist nicht, perfekte Daten anzustreben. Es geht darum, die Datensätze zu korrigieren, die die größte operative Auswirkung haben.
Beginnen Sie mit Geschäftsauswirkungen, nicht mit Datenvollkommenheit
Eine nützliche Reihenfolge sieht wie folgt aus:
Definieren Sie das Geschäftsergebnis
Entscheiden Sie, was saubere Daten schützen oder verbessern müssen. Für Marketing könnte das E-Mail-Zustellbarkeit, Segmentierungsgenauigkeit oder Attributionszuverlässigkeit sein. Für Sales könnten es Routing- und Sequenzeffizienz sein.Profilen Sie den aktuellen Zustand
Überprüfen Sie die Datenbank auf Duplikate, fehlende Werte, inkonsistente Formate, ungültige E-Mails und veraltete Datensätze. Dieser Schritt sollte Fehlerklassen erzeugen, nicht nur eine lange Liste von Fehlern.Standardisieren Sie, was nie variieren sollte
Normalisieren Sie Felder wie Namen, Länder, Bundesländer, Telefon formate, Lebenszyklus-Phasen und Quellenwerte. Standardisierung beseitigt Mehrdeutigkeit, bevor Sie versuchen, zu analysieren oder zu automatisieren.Deduplizieren und sorgfältig zusammenführen
Löschen Sie nicht einfach verdächtige Duplikate. Entscheiden Sie, welcher Datensatz das Quellensystem ist und wie Engagement, Eigentümerschaft und Einwilligungsverlauf zusammengeführt werden sollten.Validieren Sie hochriskante Felder vor der Verwendung
Kundenorientierte Felder verdienen strengere Überprüfungen als weniger wichtige Metadaten. E-Mail-Adressen, Einwilligungsindikatoren und Personalisierungsfelder sollten validiert werden, bevor sie Kampagnen auslösen.
Dies ist auch der Punkt, an dem Tools ins Spiel kommen. Für Teams, die sich speziell auf Kontaktdaten konzentrieren, ist BillionVerify ein professioneller E-Mail-Verifizierungsdienst, der ein Problem löst: Schlechte E-Mail-Daten kosten Unternehmen Geld.
Verwenden Sie ein einfaches Priorisierungsmodell
Eine Auswirkungs-Aufwand-Matrix hält die Arbeit praktisch.
Hohe Auswirkung, geringer Aufwand
E-Mail-Verifizierung, Duplikatsunterdrückung und Formatierungsnormalisierung gehören normalerweise hier hin. Diese Korrektionen verbessern oft schnell die Kampagnenleistung.Hohe Auswirkung, hoher Aufwand
Systemübergreifende Identitätsauflösung und CRM-Feldverwaltung passen in diese Kategorie. Sie sind wertvoll, erfordern aber Eigentümerschaft und Prozessdisziplin.Geringe Auswirkung, geringer Aufwand
Kosmetische Bereinigung und Feldbezeichnung-Aufräumen können später erfolgen, es sei denn, sie blockieren Berichte.Geringe Auswirkung, hoher Aufwand
Vermeiden Sie diese am Anfang. Teams verschwenden oft Zeit damit, obskure Legacy-Felder zu bereinigen, die keine Auswirkungen auf Einnahmegenerierung haben.
Viele Marketing-Ops-Teams machen den Fehler, mit umfassender CRM-Bereinigung zu beginnen, wenn sie mit aktiv in Kampagnen verwendeten Datensätzen beginnen sollten. Wenn die E-Mail-Datei schmutzig ist, wird nichts anderes fair getestet. Das ist einer der Gründe, warum praktische Leitlinien zur Listenwartung wie was Listenbereinigung für E-Mail-Leistung bedeutet in der operativen Planung so nützlich sind.
Erstellen Sie Kontrollen, bevor der nächste Upload wieder alles bricht
Bereinigung ohne Kontrollen schafft eine Rückschleife von Wiederholungsarbeiten. Die Datenbank sieht eine Woche besser aus, dann führt der nächste Import, das nächste Formular, die Synchronisation oder eine manuelle Aktualisierung dieselben Mängel wieder ein.
Verwenden Sie Kontrollen wie:
- Eingabevalidierung für Formulare und Importe
- Feldregeln für Standardwerte
- Duplikat-Überprüfungslogik vor der Datensatzerstellung
- Eigentumsregeln für wer sensible Felder bearbeiten kann
- Geplante Audits für aktive Kampagnenlisten
Das Ziel ist nicht eine einmalige Reinigung. Es geht um weniger zukünftige Kontamination.
Lösung des E-Mail-Datenproblems durch Verifizierung
E-Mail verdient eine separate Behandlung, da ein fehlerhaftes Feld zu unmittelbarem finanziellen Schaden führen kann. Ein falsch geschriebener Jobtitel kann die Berichterstattung verzerren. Eine ungültige oder riskante E-Mail-Adresse verschwendet Sendevolumen, erhöht die Akquisitionskosten, schadet der E-Mail-Zustellbarkeit und verzerrt die Kampagnenergebnisse so sehr, dass Teams falsche Budgetentscheidungen treffen.
Warum E-Mail eine spezialisierte Verifizierung benötigt
Formatprüfungen erfassen nur die offensichtlichen Fehler. Sie bestätigen nicht, ob ein Postfach E-Mail empfangen kann, ob die Adresse zu einem Disposable-Provider gehört, oder ob das Versenden an diese Adresse ein Reputationsrisiko schafft.
Diese Unterscheidung ist in Umsatzprogrammen wichtig. Wenn ein bezahltes Lead-Formular falsche oder temporäre Adressen akzeptiert, bleibt das Problem nicht in der Datenbank. Marketing zahlt für den Erwerb nicht nutzbarer Datensätze, Vertrieb folgt toten Kontakten nach, und die Kampagnenberichterstattung übertreibt die Listengröße, während sie die wahre Conversion-Rate unterschätzt. Ich habe Teams gesehen, die Kreativität, Angebot und Timing beschuldigen, wenn das zugrunde liegende Problem war, dass viel zu viel der Datei niemals hätte versendet werden sollen.
Ein Verifizierungstool wie BillionVerify überbrückt diese Lücke, indem es Zustellbarkeitssignale in Echtzeit prüft und riskantere Adressen kennzeichnet, bevor sie die Leistung beeinflussen. Wenn Sie Ansätze über Anbieter und Prozesse hinweg vergleichen, ist es hilfreich zu überprüfen, wie andere Teams Qualität der Marketing-Liste sicherstellen, bevor Sie entscheiden, welches Verifizierungsniveau Sie benötigen.
Wo Verifizierung in den Arbeitsablauf passt
Verifizierung hat die höchste Rentabilität in drei operativen Punkten:
Am Einstiegspunkt
Validieren Sie Adressen während der Registrierung, Lead-Erfassung und Formularübermittlung, damit fehlerhafte Datensätze gar nicht erst in das CRM gelangen.Vor großen Kampagnen Überprüfen Sie die aktive Sendliste vor Produktstarts, Aktionen und Re-Engagement-Sends. Teams erholen sich meist am schnellsten von verschwendetem Volumen während dieser Aktivität.
Nach einem wiederkehrenden Hygiene-Plan
E-Mail-Daten verfallen. Verifizierung sollte in der Routine-Listenwartung enthalten sein, damit die Datei nicht in das gleiche Fehlermuster zurückfällt.
Teams, die die praktische Mechanik verstehen möchten, sollten mit einer klaren Erklärung von wie E-Mail-Verifizierung in der Praxis funktioniert beginnen. Sobald der Prozess klar ist, wird es viel einfacher, Verifizierung in Formulare, CRM-Syncs und Vor-Send-Checks einzubauen, ohne die Ausführung zu verlangsamen.
Messung der ROI von sauberen Daten
Schlechte Datenqualität kostet Organisationen durchschnittlich 12,9 Millionen Dollar pro Jahr, laut Gartner. Deshalb funktionieren ROI-Gespräche rund um die Datenbereinigung besser, wenn sie mit finanziellen Begriffen beginnen, nicht mit technischen.
Ein einfaches Modell reicht aus, um ein ernstes Gespräch in Gang zu bringen:
ROI = (Gewonnener Wert + Vermiedene Kosten) / Investitionskosten
Ich verwende diese Struktur, weil sie widerspiegelt, wie schlechte Daten die Marketing-P&L beeinflussen. Einige Verluste zeigen sich als entgangene Einnahmen. Andere liegen in verschwendeten Ausgaben, manueller Überarbeitung, Compliance-Risiken und langsamerer Entscheidungsfindung.
Ein praktischer Weg zur Geschäftsbegründung
Beginnen Sie mit Positionen, die ein Marketing-Direktor bereits besitzt oder beeinflussen kann:
- Verschwendete Kampagnenausgaben durch das Senden an Datensätze, die sich nie konvertieren werden
- Entgangene Einnahmen durch niedrigere E-Mail-Zustellbarkeit, schlechte Zielausrichtung oder fehlerhafte Personalisierung
- Stunden für Operations und Analysten, die für die Behebung vermeidbarer Felderfehler, Duplikate und schlechter Verknüpfungen aufgewendet werden
- Compliance-Risiken, die mit schwachen Zustimmungsdatensätzen und inkonsistenter CRM-Hygiene verbunden sind
- Marken- und Kundenvertrauenskosten, wenn die falsche Person mehr als einmal die falsche Nachricht erhält
Der Fehler, den ich in Budgetanfragen sehe, ist, dass Teams nur die positiven Seiten zählen. Finanzleiter möchten auch sehen, welche Verluste das Unternehmen nicht mehr erleidet. Dies umfasst das Risiko durch schwache Aufbewahrungskontrollen, ungenaue Zustimmungsstatus und unvollständige Kontakthistorien. Wie bereits erwähnt, bleiben Datenqualitätsprobleme nicht im Operations-Team. Sie beeinflussen gleichzeitig die Kampagneneffizienz, das Vertrauen in die Berichterstattung und die Audit-Bereitschaft.
Business-Case-Perspektive: Positionieren Sie die Datenbereinigung als Umsatzschutz- und Gewinnmargenverbesserungsinitiative. Diese Rahmung erhält normalerweise schneller Aufmerksamkeit als ein generisches Qualitätsargument.
Trennen Sie Gewinne von vermiedenen Verlusten
Die saubersten ROI-Modelle verwenden zwei Kategorien.
Gewonnener Wert umfasst messbare Leistungsverbesserungen: mehr Nachrichten, die echte Empfänger erreichen, bessere Konvertierung aus saubereren Zielgruppensegmenten und Berichte, denen Sie vertrauen können, wenn Sie Ausgaben zwischen Kanälen oder Kampagnen verschieben.
Vermiedene Kosten umfassen die Verluste, die verschwinden: weniger verschwendete Sends, weniger Stunden für die manuelle Reparatur von Datensätzen, weniger Risiko vermeidbarer Compliance-Probleme und weniger Reputationsschäden des Absenders, die die zukünftige Kampagnenleistung beeinträchtigen können.
Halten Sie die Schätzung in den Workflows verwurzelt, die Ihr Team kontrolliert. Wenn E-Mail der Kundendatenstrom mit dem höchsten Volumen ist, beginnen Sie dort. Ein Marketingteam benötigt kein unternehmensweites Master-Datenmodell, um Maßnahmen zu rechtfertigen. Es benötigt eine verteidigbare Schätzung eingesparter Ausgaben, geschützten Umsatzes und reduzierter Nacharbeiten. Für Teams, die dieses Modell aufbauen, bietet diese Anleitung zum Berechnen der E-Mail-Verifizierungs-ROI eine nützliche Planungsstruktur.
Von einmaliger Behebung zu einer proaktiven Datenstrategie
Unternehmen, die Daten gut verwalten, warten nicht auf ein Dashboard-Problem oder einen Zustellbarkeitsvorfall, um zu handeln. Sie etablieren Routinen, die verhindern, dass schlechte Datensätze zunächst in kritische Systeme gelangen.
Das bedeutet normalerweise, dass drei Gewohnheiten zum Standard werden. Erstens: Validieren Sie Daten an der Erfassungsstelle, besonders bei Kundenformularen und Kampagnenlisten. Zweitens: Führen Sie wiederkehrende Audits der Datensätze durch, die Outreach und Reporting antreiben. Drittens: Definieren Sie die Zuständigkeiten, damit Mitarbeiter wissen, wer Felder ändern, Datensätze zusammenführen und Importe genehmigen darf.
Es gibt auch hier einen strategischen Mentalitätswechsel. Saubere Daten sind nicht der Endzustand. Es ist eine Wartungsdisziplin. Datensätze ändern sich, Kontakte veralten, Inboxen verfallen, und Übergaben zwischen Plattformen schaffen neue Inkonsistenzen. Teams, die die Bereinigung als einmalige Projektaufgabe behandeln, zahlen am Ende zweimal für die gleichen Fehler.
Saubere Systeme bleiben nicht durch Zufall sauber. Jemand legt die Regeln fest, jemand überwacht die Ausnahmen, und jemand behebt die Grundursachen, statt wiederholt die Symptome zu bereinigen.
Für Marketing-Leiter wird diese Disziplin zu einem Wettbewerbsvorteil. Kampagnen werden mit weniger Überraschungen gestartet. Reporting wird vertrauenswürdiger. Sales verbringt weniger Zeit damit, die Lead-Qualität in Frage zu stellen. Compliance-Überprüfungen werden weniger belastend. Und die E-Mail-Performance spiegelt die Strategie genauer wider, weil die Liste die Kampagne nicht behindert.
Wenn E-Mail-Daten eine der größten Verschwendungsquellen in Ihrem Funnel sind, lohnt sich BillionVerify als Teil eines umfassenderen Hygieneprogramms zu evaluieren. Es erfüllt das praktische Bedürfnis vieler Organisationen: Adressen vor dem Versand verifizieren, Einweg- und riskante Einträge frühzeitig erkennen und die betriebliche Belastung reduzieren, die schlechte E-Mail-Daten verursachen.