


Slechte gegevenskwaliteit kan een aanzienlijk deel van de inkomsten opslokken. IBM meldt dat slechte gegevenskwaliteit de Amerikaanse economie $3,1 biljoen per jaar kost (IBM-schatting van de kosten van slechte gegevens). Voor een marketingdirecteur is dat geen abstract data governance-probleem. Het manifesteert zich als betaalde media die naar ongeldige contacten worden verzonden, verkooptijd verspild aan slechte leads, zwakkere segmentatie en attributierapporten die gezonde campagnes als kapot doen lijken.
Ik heb hetzelfde patroon gezien in demand generation teams. Een lijst kan groot genoeg lijken om pipelinedoelen te bereiken terwijl deze duplicaatrecords, verouderde e-mails en opmaakerrors verbergt die de reactiesnelheid verlagen en acquisitiekosten opvoeren. E-mail is meestal de snelste plaats om het verlies te zien, daarom schone e-maillijsten zijn belangrijk voor campagneprestaties en afzendersreputatie.
De zakelijke vraag is eenvoudig. Wat zijn de kosten van het nog een kwartaal in stand houden van slechte records?
Deze kosten duiken op twee plekken op. Ten eerste is er direct verspilling: extra verzendingen, hogere platformkosten, lagere conversie van verkeerd gerichte campagnes en SDR-uren besteed aan records die nooit het systeem hadden mogen binnenkomen. Ten tweede is er stroomafwaartse schade aan de besluitvorming. Als leidbron, firmografische velden of engagement history onjuist zijn, financiert het team de verkeerde kanalen en snijdt het de juiste kanalen af. Daarom beginnen sterke dataprogramma's met zakelijke impact, niet met databaseperfectie, een punt dat wordt ondersteund door Orbit AI data quality insights.
Data cleaning verdient budget wanneer teams het behandelen als inkomstenbescherming met meetbare ROI, niet als routine onderhoud.
Gegevensopschoning Is een Opbrengstenstrategie, Niet een IT-Taak
Veel organisaties spreken nog steeds over gegevensopschoning alsof het administratief werk is. Dat is een fout. Wanneer revenue teams naar ongeldige contacten sturen, personaliseren vanuit beschadigde records, of segmenteren op verouderde velden, hebben zij niet te maken met een technische hindernis. Ze financieren slechte prestaties.
De reden waarom gegevensopschoning belangrijk is, heeft minder te maken met nette databases en meer met uitvoeringskwaliteit. Marketing kan sterk creatief werk produceren, slimme aanbiedingen doen en gedisciplineerde campagneplanning voeren, vervolgens prestaties verliezen omdat het contactbestand op het moment van verzending niet klopt. Sales kan in een veelbelovend gebied werken, dan ontdekken dat de CRM vol staat met duplicaten, verouderde functies en slechte e-mailadressen. Productteams kunnen aanmeldingsgedrag bestuderen, vervolgens beslissingen trainen op gebrekkige gegevens.
Veel van het sterkste operationele denken in dit gebied behandelt nu gegevenshygiëne als een bedrijfssysteem, niet als een eenmalige opschoning. De benadering in Orbit AI data quality insights is nuttig omdat het gegevenskwaliteit verbindt met operationele betrouwbaarheid in plaats van het als een geïsoleerde databasetaak te behandelen.
Praktische regel: Als een veld doelgerichtheid, personalisatie, routering of rapportage beïnvloedt, is het geen IT-veld. Het is een opbrengstenveld.
Die mentaliteitsverandering is belangrijk omdat slechte contactgegevens de neiging hebben zich achter kanaalmetrieken te verschuilen. Teams geven de schuld aan onderwerpsregels, kwaliteit van het aanbod of vervolgsnelheid wanneer de lijst zelf het probleem is. Vooral in e-mailprogramma's bepaalt de kwaliteit van de lijst of de campagne eigenlijk een eerlijke kans krijgt. Daarom beginnen veel teams met het verstevigen van lijstenhygiëne en het beoordelen van bronnen zoals waarom schone e-mailijsten belangrijk zijn voordat zij elders hun strategie veranderen.
De Anatomie van Vuile Gegevens
Vuile gegevens creëren operationeel risico lang voordat iemand het een datakwaliteitsprobleem noemt. In de praktijk doet het zich voor als een betaalde campagne die naar ongeldige inboxen wordt verzonden, leads die naar de verkeerde vertegenwoordiger worden gerouteerd, dubbele contacten die pipelinecijfers opblazen, of toestemmingsgegevens die niet meer overeenkomen met wat marketing mag verzenden.
Binnen CRMs, ESPs, aanmeldingsformulieren, verrijkingstools en BI-platforms kondigen slechte records zich zelden aan. Ze zien er bruikbaar uit totdat een team probeert te segmenteren, routeren, personaliseren, rapporteren of ervan te voorspellen. Daarom is vuile data duur. Het mislukt op het moment van gebruik, nadat budget, tijd en besluitvorming al zijn vastgelegd.
Vuile gegevens verschijnen in vijf vertrouwde vormen
Dit zijn de falingspatronen die het merendeel van de operationele wrijving veroorzaken:
Onvolledige records
Ontbrekende velden breken segmentatieregels, leadscoring, routeringslogica en personalisatie. Een contactpersoon zonder een geldig e-mailadres, regio of levenscyclusfase kan maandenlang in de database zitten en nog steeds onbruikbaar zijn wanneer de campagne live gaat.Onnauwkeurige vermeldingen
Typefouten, nepinvoer, misvormde adressen en onjuiste bedrijfsgegevens creëren vals vertrouwen. De record bestaat, maar het team kan er niet op vertrouwen.Dubbele records
Duplicaten splitsen betrokkenheidsgeschiedenis, toewijzing en eigendom. Marketing kan een record onderdrukken en een ander verzenden. Verkoop kan dezelfde koper twee keer bellen. Rapportage telt activiteit over twee profielen en geeft prestaties verkeerd weer.Inconsistente opmaak
Dezelfde bedrijfsnaam, land of functie verschijnt in verschillende indelingen. Filteren wordt onbetrouwbaar, matchingregels missen duidelijke overlaps, en teams beginnen rapporten handmatig in spreadsheets te repareren.Verouderde gegevens
Mensen veranderen van baan, afdelingen fuseren, inboxen worden inactief en de toestemmingsstatus verandert in de loop van de tijd. Gegevensverval is normaal. De operationele fout is gisteren's geldige record vandaag nog als veilig te gebruiken.
Voor e-mailteams convergeren deze problemen vaak in één lijst. Één bestand kan tegelijkertijd verlaten inboxen, rolaccounts, catch-all domeinen, duplicaten en opmaakfouten bevatten. Een praktische uitleg van wat lijstschoonmaak inhoudt voor e-mailprestaties helpt duidelijk te maken waarom "een paar slechte contacten verwijderen" een te nauw gezichtspunt van het probleem is.
Schoonmaak wordt ook verward met verzameling. Het zijn verschillende taken. Als u meer records aan een verbroken systeem toevoegt, neemt meestal het aantal fouten toe, omdat dezelfde zwakke validatieregels, veldstandaarden en synchronisatieproblemen steeds nieuwe slechte vermeldingen produceren.
Het proces zelf is goed vastgesteld. Het technische overzicht in de gegevensschoonmaakwerkstroom beschrijft kernstappen zoals het verwijderen van duplicaten, het omgaan met ontbrekende waarden, het standaardiseren van indelingen, het valideren van volledigheid en het controleren van nauwkeurigheid vóór analyse of activering. Dit werk gaat vooraf aan rapportagekwaliteit, automatiseringskwaliteit en modelkwaliteit.
Het principe van garbage in, garbage out is een letterlijke beschrijving van wat er in de bedrijfsvoering gebeurt. Rapporten weerspiegelen slechte invoer. Automatiseringen activeren onder de verkeerde voorwaarden. Modellen leren van records die nooit productiesystemen hadden mogen bereiken.
De Kwantificeerbare Schade van Data Decay
Slechte datakwaliteit kost organisaties gemiddeld $12.9 miljoen per jaar, volgens IBM. Dit opvallende getal trekt aandacht, maar de operationele schade is gemakkelijker over het hoofd te zien omdat deze in tientallen regelposten verschijnt: verspilde mediabudget, lagere conversieratio's, slechte prognoses en klantenervaringen die onzorgvuldig aanvoelen in plaats van gecoördineerd (IBM via Experian).
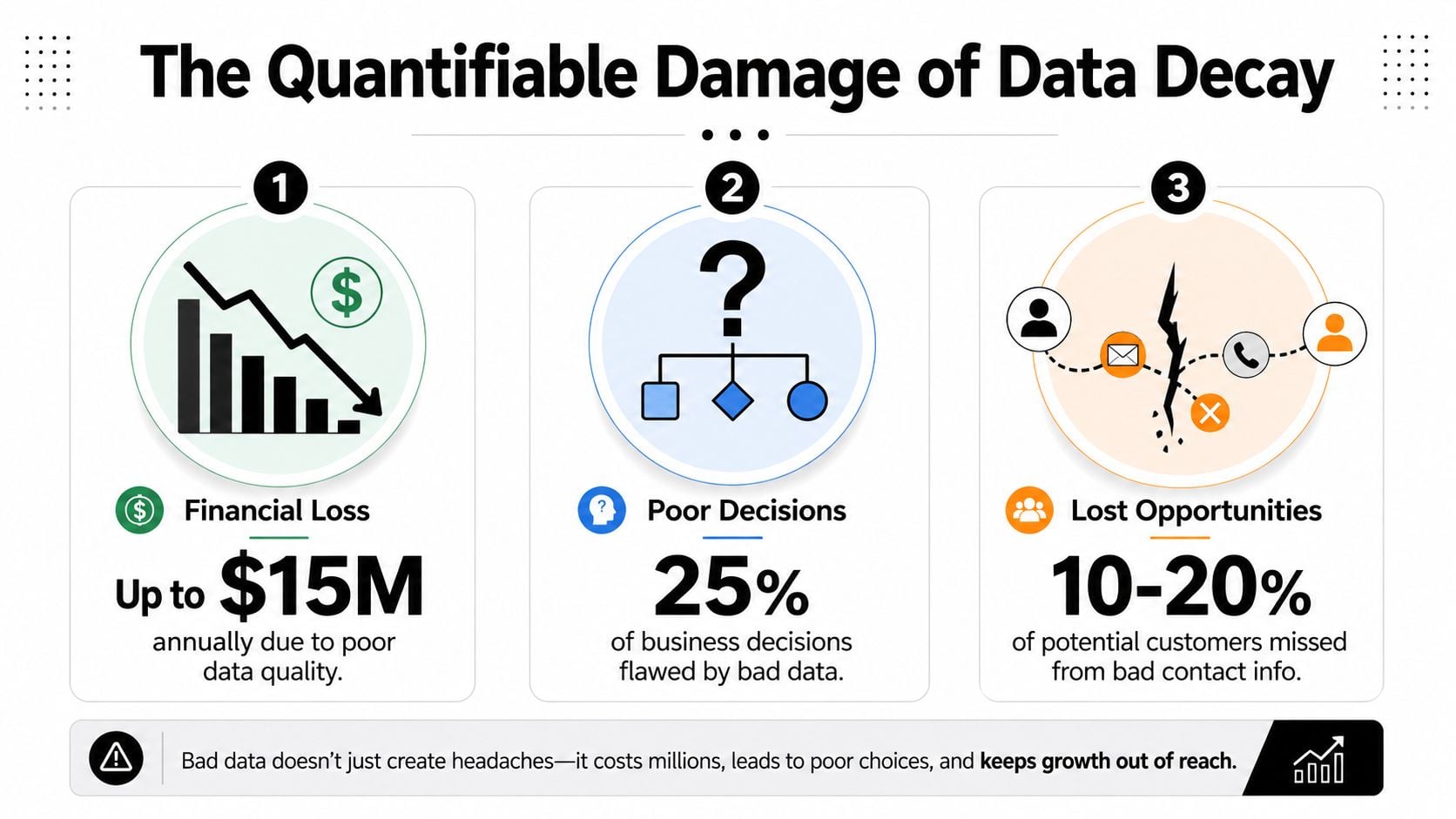
Kleine lijstproblemen worden grote financiële lekkages
E-mail maakt de kosten snel zichtbaar. Als 10% van een contactlijst van 100.000 contacten ongeldig is en je betaalt nog steeds voor het werven of bereiken van deze contacten, wordt het budget al verbruid voordat de campagne een kans heeft om goed uit te voeren. Dan volgen de vervolgsgekosten. Hogere bouncepercentages schaden de inbox plaatsing, wat de waarde van de geldige adressen die je nog hebt vermindert.
Daarom controleren afleveringsteams bouncepercentage als een winstmaatstaf, niet alleen als een e-mailmetriek. Een praktische uitleg van waarom bouncepercentages van belang zijn voor campagnesucces toont hoe contactlijstverval transformeert in afzendersreputatieproblemen die toekomstige verzendingen beïnvloeden, niet alleen de huidige.
Ik heb dit in driemaandelijkse beoordelingen zien gebeuren. Marketing rapporteert een creatief of aanbod probleem. Het onderliggende probleem is lijstkwaliteit. Het team blijft teksten optimaliseren terwijl mailbox providers inbox plaatsing blijven verminderen.
De fix begint met betere inputs. Teams die adressen verifiëren vóór lancering en tussen campagnes kunnen marketing lijstkwaliteit waarborgen en stoppen met betalen om berichten te verzenden die nooit afleverbaar waren.
Slechte records vervormen beslissingen nadat de campagne is afgelopen
De grotere kosten verschijnen vaak na verzending. Vuile gegevens beschadigen attributie, doelgroepbeschrijvingen en prestatierapportage. Als dubbele records de betrokkenheidsgeschiedenis over twee profielen splitsen, kan één klant eruit zien als twee zwakke leads in plaats van één gekwalificeerde koper. Als levenscyclusfase of toestemmingsstatus verouderd is, wordt het verkeerde publiek in de verkeerde cohort geteld. Dit verandert budgetbeslissingen.
Gartner heeft geschat dat slechte datakwaliteit organisaties gemiddeld $12.9 miljoen per jaar kost, en dit getal helpt verklaren waarom slechte records meer dan technisch opschoonwerk veroorzaken. Ze produceren financiële fouten op managementniveau, omdat teams budget, personeelssterkte en kanaal mix toewijzen op basis van rapporten die ze niet kunnen vertrouwen (Gartner, hier aangehaald).
Klantenervaringen krijgen ook een klap. Twilio Segment ontdekte dat 56% van consumenten terugkerende klanten worden na een gepersonaliseerde ervaring, wat betekent dat onnauwkeurige personalisatie een direct opbrengstverlies tot gevolg heeft wanneer de onderliggende gegevens onjuist zijn (Twilio Segment personalisatierapport). Dubbele contacten, verouderde voorkeuren en onjuiste identificatoren leiden tot herhaalde berichten, irrelevante aanbevelingen en duidelijke CRM fouten die signaleren dat het merk niet oppast.
Hier is het zakelijke patroon:
| Operationeel probleem | Onmiddellijk effect | Zakelijk gevolg |
|---|---|---|
| Ongeldige e-mailadressen | Meer bounces | Verspild verzendbudget en lagere inbox plaatsing |
| Dubbele contacten | Gesplitste histories en herhaalde contactpogingen | Slechte klantenervaringen en onbetrouwbare attributie |
| Onjuiste CRM velden | Foutieve segmentatie | Fout gerichte campagnes en gemiste conversiemogelijkheden |
| Verouderde toestemming of klantenstatus | Berichten naar het verkeerde publiek | Compliance blootstelling en merkschade |
Een paar slechte records blijven niet klein. Ze verspreiden zich via rapportage, automatisering, doelgerichtheid en klantcontactpunten totdat een data hygiene probleem een opbrengst probleem wordt.
Een praktisch framework voor gegevensschoon
Zodra teams erkennen dat gegevenskwaliteit omzet beïnvloedt, is het volgende probleem prioritering. De meeste databases bevatten te veel problemen om alles tegelijk op te schonen. De juiste stap is niet perfect data na te streven. Het gaat erom de records op te lossen die de grootste operationele impact hebben.
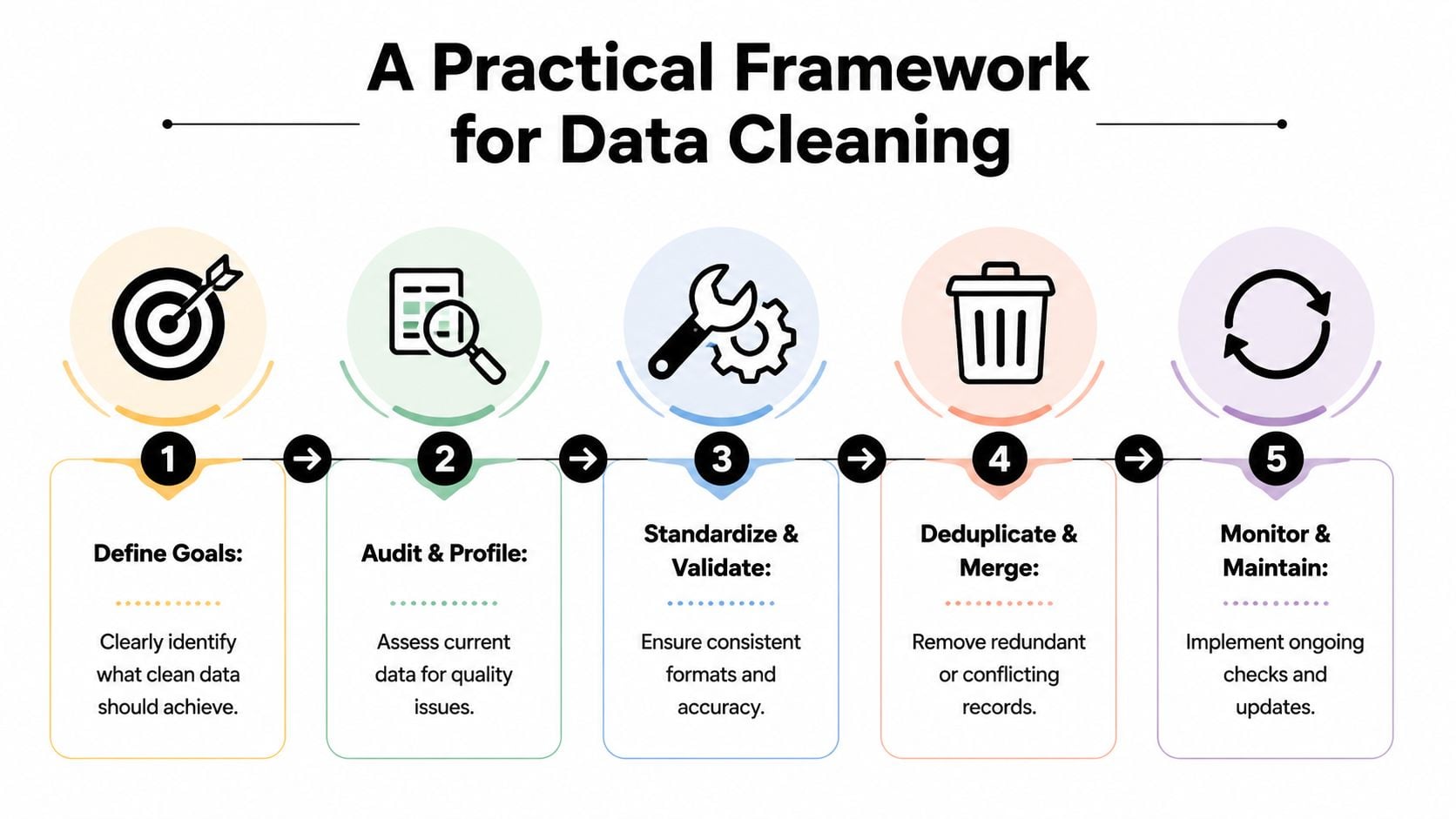
Begin met zakelijk effect, niet met dataperfectie
Een nuttige volgorde ziet er als volgt uit:
Definieer het zakelijke resultaat
Bepaal wat schone gegevens moeten beschermen of verbeteren. Voor marketing kan dat afleveringstarief, segmentatienauwkeurigheid of attributiebetrouwbaarheid zijn. Voor verkoop kan het routering en volgordefficiëntie zijn.Profiel de huidige staat
Controleer de database op duplicaten, ontbrekende waarden, inconsistente indelingen, ongeldige e-mails en verouderde records. Deze stap moet categorieën van fouten opleveren, niet alleen een lange lijst met fouten.Standaardiseer wat nooit mag variëren
Normaliseer velden zoals namen, landen, staten, telefoonindelingen, levenscyclusfasen en bronwaarden. Standaardisering verwijdert dubbelzinnigheid voordat u probeert te analyseren of te automatiseren.Zorgvuldig dedupliceren en samenvoegen
Verwijder niet zomaar vermoedelijke duplicaten. Bepaal welke record het systeem van registratie is en hoe betrokkenheid, eigendom en toestemmingsgeschiedenis moeten worden samengevoegd.Valideer risicovolle velden vóór gebruik
Klantgerichte velden verdienen strengere controles dan metagegevens met lage impact. E-mailadressen, toestemmingsindicatoren en personalisatievelden moeten worden gevalideerd voordat zij campagnes triggeren.
Dit is ook waar tools het gesprek binnenkomen. Voor teams die zich specifiek richten op contactgegevens, is BillionVerify een professionele e-mailverificatieservice die is gebouwd om één probleem op te lossen: slechte e-mailgegevens kosten bedrijven geld.
Gebruik een eenvoudig prioriteringsmodel
Een impact-versus-inspanningsmatrix houdt het werk praktisch.
Hoge impact, lage inspanning
E-mailvalidatie, duplicaatonderdrukking en opmaaktnormalisering horen hier meestal thuis. Deze fixes verbeteren de campagneprestaties vaak snel.Hoge impact, hoge inspanning
Cross-systeem identiteitsresolutie en CRM-veldbestuur passen in deze categorie. Ze zijn het waard om te doen, maar ze hebben eigendom en procesdiscipline nodig.Lage impact, lage inspanning
Cosmetische opschoning en veldlabelverzorging kunnen later gebeuren, tenzij ze rapportage blokkeren.Lage impact, hoge inspanning
Vermijd deze in een vroeg stadium. Teams verbranden vaak tijd met het schoonmaken van duistere legacy-velden die geen invloed hebben op inkomstenactiviteiten.
Veel marketing ops-teams maken de fout om te beginnen met brede CRM-opschoning, terwijl ze zouden moeten beginnen met de records die actief in campagnes worden gebruikt. Als het e-mailbestand vuil is, krijgt niets anders een eerlijke test. Dat is één reden waarom praktische richtlijnen voor lijstonderhoud, zoals wat lijstschoon betekent voor e-mailprestaties, zo nuttig zijn in operationele planning.
Bouw controles in voordat de volgende upload alles opnieuw kapot maakt
Schoonmaken zonder controles creëert een lus van herwerk. De database ziet er een week beter uit, maar dan voert de volgende import, formulier, synchronisatie of handmatige update dezelfde gebreken opnieuw in.
Gebruik controles zoals:
- Invoervalidatie voor formulieren en imports
- Veldregels voor standaardwaarden
- Logica voor duplicaatbeoordeling vóór recordcreatie
- Eigendomsregels voor wie gevoelige velden kan bewerken
- Geplande audits voor actieve campagnelijsten
Het doel is geen eenmalige reiniging. Het gaat erom toekomstige besmetting te verminderen.
Het e-mailgegevensprobleem met verificatie oplossen
E-mail verdient aparte behandeling omdat één slecht veld onmiddellijk financieel verlies kan veroorzaken. Een verkeerd gespelde functietitel kan de rapportage vertekenen. Een ongeldig of riskant e-mailadres verspilt verzendvolume, verhoogt verwervingskosten, schaadt deliverability en vervormt campagneresultaten zodanig dat teams verkeerde budgetbeslissingen nemen.
Waarom e-mail gespecialiseerde verificatie nodig heeft
Formaatcontroles vangen alleen de duidelijke fouten op. Ze bevestigen niet of een mailbox e-mail kan ontvangen, of het adres van een wegwerpprovider afkomstig is, of verzenden ervan reputatierisico creëert.
Dit onderscheid is belangrijk in inkomstenprogramma's. Als een betaalde leadformulier nep- of tijdelijke adressen accepteert, blijft het probleem niet in de database. Marketing betaalt voor onbruikbare records, verkoop volgt dode contacten op, en campagnerapportage overschat de lijstgrootte terwijl het werkelijke conversiepercentage wordt onderschat. Ik heb teams zien de schuld geven aan creatief, aanbod en timing wanneer het onderliggende probleem was dat te veel van het bestand nooit per post had moeten worden verzonden.
Een verificatiegereedschap zoals BillionVerify sluit deze kloof door deliverability-signalen in real-time te controleren en adressen met hoger risico aan te geven voordat deze de prestaties beïnvloeden. Als je benaderingen tussen leveranciers en processen vergelijkt, is het handig om te beoordelen hoe andere teams de kwaliteit van marketinglijsten waarborgen voordat je besluit welk verificatieniveau je nodig hebt.
Waar verificatie in de workflow past
Verificatie heeft het grootste rendement op drie operationele punten:
Op het moment van invoer
Valideer adressen tijdens aanmelding, leadregistratie en formulierverzending zodat slechte records niet in de eerste plaats in het CRM terechtkomen.Vóór grote campagnes
Controleer de actieve verzendlijst vóór productlanceringen, promoties en hernieuwde betrokkenheidsberichten. Teams herstellen verspild volume meestal het snelst tijdens deze activiteit.Op een regelmatig onderhoudschema
E-mailgegevens verouderen. Verificatie moet onderdeel zijn van routine-onderhoudslijsten zodat het bestand niet teruggaat naar hetzelfde foutpatroon.
Teams die de praktische mechanica willen begrijpen, moeten beginnen met een duidelijke uitleg van hoe e-mailverificatie in de praktijk werkt. Zodra het proces duidelijk is, wordt het veel gemakkelijker om verificatie in formulieren, CRM-synchronisaties en voorverzendcontroles in te voegen zonder de uitvoering te vertragen.
Het ROI meten van schone gegevens
Slechte gegevenskwaliteit kost organisaties gemiddeld $12,9 miljoen per jaar, volgens Gartner. Daarom verlopen ROI-gesprekken over gegevensreiniging beter wanneer ze beginnen in financiële termen, niet in technische.
Een eenvoudig model is genoeg om een serieus gesprek op gang te brengen:
ROI = (Behaalde waarde + Vermeden kosten) / Investeringskosten
Ik gebruik deze structuur omdat ze weerspiegelt hoe slechte gegevens een marketing P&L treffen. Sommige verliezen verschijnen als gemiste inkomsten. Anderen bevinden zich in verspilde uitgaven, handmatig werk, nalevingsrisico en langzamere besluitvorming.
Een praktische manier om de zakelijke zaak op te bouwen
Begin met regelposten die een marketingdirecteur al bezit of kan beïnvloeden:
- Verspilde campagnebegroting van verzending naar records die nooit zullen converteren
- Verloren inkomsten van zwakkere afleveringscapaciteit, slechte doelgerichtheid of verbroken personalisatie
- Ops- en analyticusuren besteed aan het repareren van voorkoombare veldfouten, duplicaten en slechte joins
- Nalevingsrisico gekoppeld aan zwakke toestemmingsregistraties en inconsistente CRM-hygiëne
- Merk- en klantvertrouwenskosten wanneer de verkeerde persoon het verkeerde bericht meer dan eens ontvangt
De fout die ik in begrotingsaanvragen zie, is dat teams alleen winst tellen. Financieel leiders willen ook zien wat het bedrijf stopt met verliezen. Dit omvat de blootstelling die wordt veroorzaakt door slechte retentiecontroles, onnauwkeurige toestemmingsstatus en onvolledige contactgeschiedenissen. Zoals eerder opgemerkt, blijven gegevenskwaliteitsproblemen niet binnen het operationele team. Ze beïnvloeden campagneeffectiviteit, rapporteringsvertrouwen en controlebereidheid tegelijkertijd.
Perspectief zakelijke zaak: Positioneer gegevensreiniging als een inkomstenbeschemings- en winstmargeverbeteringsinitiatieven. Deze framing krijgt meestal sneller grip dan een algemeen kwaliteitsbetoog.
Scheiding van opbrengsten van vermeden verliezen
De schoonste ROI-modellen gebruiken twee categorieën.
Behaalde waarde omvat meetbare prestatieverbeteringen: meer berichten bereiken werkelijke ontvangers, betere conversie van schonere doelgroepsegmenten, en rapportage waarop u kunt vertrouwen bij het verschuiven van uitgaven tussen kanalen of campagnes.
Vermeden kosten omvat de verliezen die verdwijnen: minder verspilde verzendingen, minder uren besteed aan het handmatig repareren van records, minder risico op vermijdbare nalevingsproblemen, en minder reputatieschade van afzenders die toekomstige campagneprestaties kan drukken.
Houd de raming gegrond in workflows die uw team beheerst. Als e-mail de gegevensstroom van de klant met het hoogste volume is, begin daar. Een marketingteam heeft geen bedrijfsbrede stamgegevensmodel nodig om actie te rechtvaardigen. Het heeft een verdedigbare schatting van teruggewonnen uitgaven, beschermde inkomsten en verminderd handmatig werk nodig. Voor teams die dat model bouwen, biedt deze gids voor berekening van ROI voor e-mailverificatie een nuttige planningsstructuur.
Van eenmalige oplossing naar proactieve gegevensstrategie
Bedrijven die goed met gegevens omgaan, wachten niet tot een dashboardprobleem of bezorgbaarheidsprobleem zich voordoet. Ze creëren routines die voorkomen dat slechte records kritieke systemen binnendringen.
Dit betekent meestal dat drie gewoonten standaard worden. Ten eerste: valideer gegevens op het moment van vastlegging, vooral voor klantgerichte formulieren en campagnelijsten. Ten tweede: voer regelmatige controles uit op records die actieve outreach en rapportage voeden. Ten derde: definieer eigendom zodat mensen weten wie velden kan wijzigen, records kan samenvoegen en importen kan goedkeuren.
Er is hier ook een strategische mentaliteitsverandering. Schone gegevens zijn niet de eindtoestand. Het is een onderhoudsdiscipline. Records veranderen, contacten verdwijnen, inboxen verlopen en handoffs tussen platforms creëren nieuwe inconsistenties. Teams die schoonmaken als een eenmalig project behandelen, betalen uiteindelijk twee keer voor dezelfde fouten.
Schone systemen blijven niet per ongeluk schoon. Iemand stelt de regels in, iemand controleert de uitzonderingen en iemand lost oorzaken op in plaats van herhaaldelijk symptomen schoon te maken.
Voor marketingleiders wordt deze discipline een concurrentievoordeel. Campagnes starten met minder verassingen. Rapportage wordt gemakkelijker te vertrouwen. Sales besteedt minder tijd aan het bevragen van leadkwaliteit. Compliance-controles worden minder pijnlijk. En e-mailprestaties weerspiegelen strategie nauwkeuriger omdat de lijst niet tegen de campagne in werkt.
Als e-mailgegevens een van de grootste bronnen van verspilling in uw trechter zijn, is BillionVerify het waard om te evalueren als onderdeel van een breder hygiëneprogramma. Het voldoet aan de praktische behoefte waarmee veel organisaties worstelen: adressen controleren voordat ze worden verzonden, eenmalige en riskante items vroegtijdig opvangen en de operationele wrijving verminderen die slechte e-mailgegevens veroorzaken.