


La mala calidad de los datos puede consumir una parte significativa de los ingresos. IBM reporta que la mala calidad de los datos cuesta a la economía de EE.UU. $3.1 billones por año (estimación de IBM sobre el costo de los datos deficientes). Para un director de marketing, esto no es un problema abstracto de gobernanza de datos. Se manifiesta como medios pagos enviados a contactos inválidos, tiempo de ventas desperdiciado en leads deficientes, segmentación más débil e informes de atribución que hacen que las campañas saludables se vean rotas.
He visto el mismo patrón en equipos de generación de demanda. Una lista puede parecer lo suficientemente grande para alcanzar los objetivos del pipeline mientras oculta registros duplicados, correos electrónicos desactualizados y errores de formato que reducen las tasas de respuesta e impulsan los costos de adquisición. El correo electrónico es generalmente el lugar más rápido para ver la pérdida, por lo que las listas de correo electrónico limpias son importantes para el rendimiento de las campañas y la reputación del remitente.
La pregunta empresarial es simple. ¿Cuál es el costo de dejar registros deficientes en su lugar durante otro trimestre?
Ese costo se distribuye en dos lugares. Primero, hay desperdicio directo: envíos adicionales, costos de plataforma más altos, menor conversión de campañas mal dirigidas y horas de SDR gastadas en registros que nunca deberían haber entrado en el sistema. Segundo, hay daño aguas abajo en la toma de decisiones. Si la fuente de leads, los campos firmográficos o el historial de compromiso son incorrectos, el equipo financia los canales equivocados y corta los correctos. Por eso los programas de datos sólidos comienzan con el impacto empresarial, no con la perfección de la base de datos, un punto reforzado por perspectivas de calidad de datos de Orbit AI.
La limpieza de datos gana presupuesto cuando los equipos la tratan como protección de ingresos con ROI medible, no como mantenimiento de rutina.
La Limpieza de Datos es una Estrategia de Ingresos, no una Tarea de TI
Muchas organizaciones todavía hablan sobre la limpieza de datos como si fuera un trabajo administrativo. Eso es un error. Cuando los equipos de ingresos envían a contactos inválidos, personalizan desde registros rotos o segmentan en campos desactualizados, no están lidiando con una molestia técnica. Están financiando el bajo rendimiento.
La razón por la que la limpieza de datos es importante tiene menos que ver con bases de datos ordenadas y más que ver con la calidad de la ejecución. Marketing puede producir creatividad sólida, ofertas inteligentes y planificación de campañas disciplinada, luego perder rendimiento porque el archivo de audiencia es incorrecto en el momento del envío. Ventas puede trabajar en un territorio prometedor, luego descubrir que el CRM está lleno de duplicados, roles desactualizados y direcciones de correo electrónico incorrectas. Los equipos de Producto pueden estudiar el comportamiento de inscripción, luego entrenar decisiones en datos defectuosos.
Mucho del pensamiento operativo más sólido en esta área ahora trata la higiene de datos como un sistema empresarial, no como una limpieza única. El enfoque en Orbit AI data quality insights es útil porque conecta la calidad de los datos con la confiabilidad operativa en lugar de tratarla como una tarea de base de datos aislada.
Regla práctica: Si un campo influye en la segmentación, personalización, enrutamiento o informes, no es un campo de TI. Es un campo de ingresos.
El cambio de mentalidad importa porque los datos de contacto defectuosos tienden a ocultarse detrás de métricas de canal. Los equipos culpan a las líneas de asunto, la calidad de la oferta o la velocidad de seguimiento de ventas cuando la lista en sí es el problema. En programas de correo electrónico especialmente, la calidad de la lista determina si la campaña tiene una oportunidad justa. Por eso muchos equipos comienzan mejorando la higiene de la lista y revisando recursos como por qué las listas de correo limpio son importantes antes de cambiar su estrategia en otros aspectos.
La anatomía de datos sucios
Los datos sucios crean riesgo operativo mucho antes de que alguien los etiquete como un problema de calidad de datos. En la práctica, aparecen como una campaña pagada enviada a bandejas de entrada inválidas, clientes potenciales enrutados al representante equivocado, contactos duplicados inflando recuentos de canales, o registros de consentimiento que ya no coinciden con lo que el marketing tiene permitido enviar.
Dentro de CRM, ESP, formularios de registro, herramientas de enriquecimiento y plataformas de BI, los registros deficientes raramente se anuncian a sí mismos. Se ven utilizables hasta que un equipo intenta segmentar, enrutar, personalizar, informar o pronosticar a partir de ellos. Por eso los datos sucios son costosos. Fallan en el punto de uso, después de que el presupuesto, el tiempo y la toma de decisiones ya se han comprometido.
Los datos sucios aparecen en cinco formas familiares
Estos son los patrones de fallo que crean la mayor parte de la fricción operativa:
Registros incompletos
Los campos faltantes rompen las reglas de segmentación, la puntuación de clientes potenciales, la lógica de enrutamiento y la personalización. Un contacto sin correo electrónico válido, región o etapa del ciclo de vida puede permanecer en la base de datos durante meses y aún ser inutilizable cuando la campaña se pone en marcha.Entradas inexactas
Los errores tipográficos, entradas falsas, direcciones mal formadas y detalles firmográficos incorrectos crean confianza falsa. El registro existe, pero el equipo no puede confiar en él.Registros duplicados
Los duplicados dividen el historial de engagement, la atribución y la propiedad. El marketing puede suprimir un registro y enviar por correo el otro. Las ventas pueden llamar al mismo comprador dos veces. La generación de informes cuenta la actividad en dos perfiles y malinterpreta el desempeño.Formato inconsistente
El mismo nombre de empresa, país o función de trabajo aparece en varios formatos. El filtrado se vuelve poco confiable, las reglas de coincidencia pierden superposiciones obvias y los equipos comienzan a corregir informes manualmente en hojas de cálculo.Datos obsoletos
Las personas cambian de trabajo, los departamentos se fusionan, las bandejas de entrada se vuelven inactivas y el estado del consentimiento cambia con el tiempo. La degradación de datos es normal. El error operativo es tratar el registro válido de ayer como el registro seguro de hoy.
Para los equipos de correo electrónico, estos problemas a menudo convergen en una lista. Un único archivo puede contener bandejas de entrada abandonadas, cuentas de rol, dominios catch-all, duplicados y errores de formato al mismo tiempo. Una explicación práctica de qué implica la limpieza de listas para el rendimiento del correo electrónico ayuda a aclarar por qué "eliminar algunos contactos malos" es una visión demasiado estrecha del problema.
La limpieza también se confunde con la recopilación. Son trabajos diferentes. Agregar más registros a un sistema roto generalmente aumenta el volumen de errores, porque las mismas reglas de validación débiles, estándares de campos y problemas de sincronización siguen produciendo nuevas entradas malas.
El proceso en sí está bien establecido. La descripción técnica en la referencia del flujo de trabajo de limpieza de datos describe pasos principales como eliminar duplicados, manejar valores faltantes, estandarizar formatos, validar integridad y verificar precisión antes del análisis o activación. Ese trabajo está aguas arriba de la calidad de informes, calidad de automatización y calidad de modelos.
El principio de entrada de basura, salida de basura es una descripción literal de lo que sucede en las operaciones. Los informes reflejan malas entradas. Las automatizaciones se activan en las condiciones incorrectas. Los modelos aprenden de registros que nunca deberían haber llegado a los sistemas de producción.
El daño cuantificable del deterioro de datos
La mala calidad de datos cuesta a las organizaciones un promedio de $12.9 millones por año, según IBM. Ese número titular capta la atención, pero el daño operacional es más fácil de pasar por alto porque aparece en docenas de elementos: gasto mediático desperdiciado, tasas de conversión más bajas, pronósticos incorrectos y experiencias de cliente que parecen descuidadas en lugar de coordinadas (IBM vía Experian).
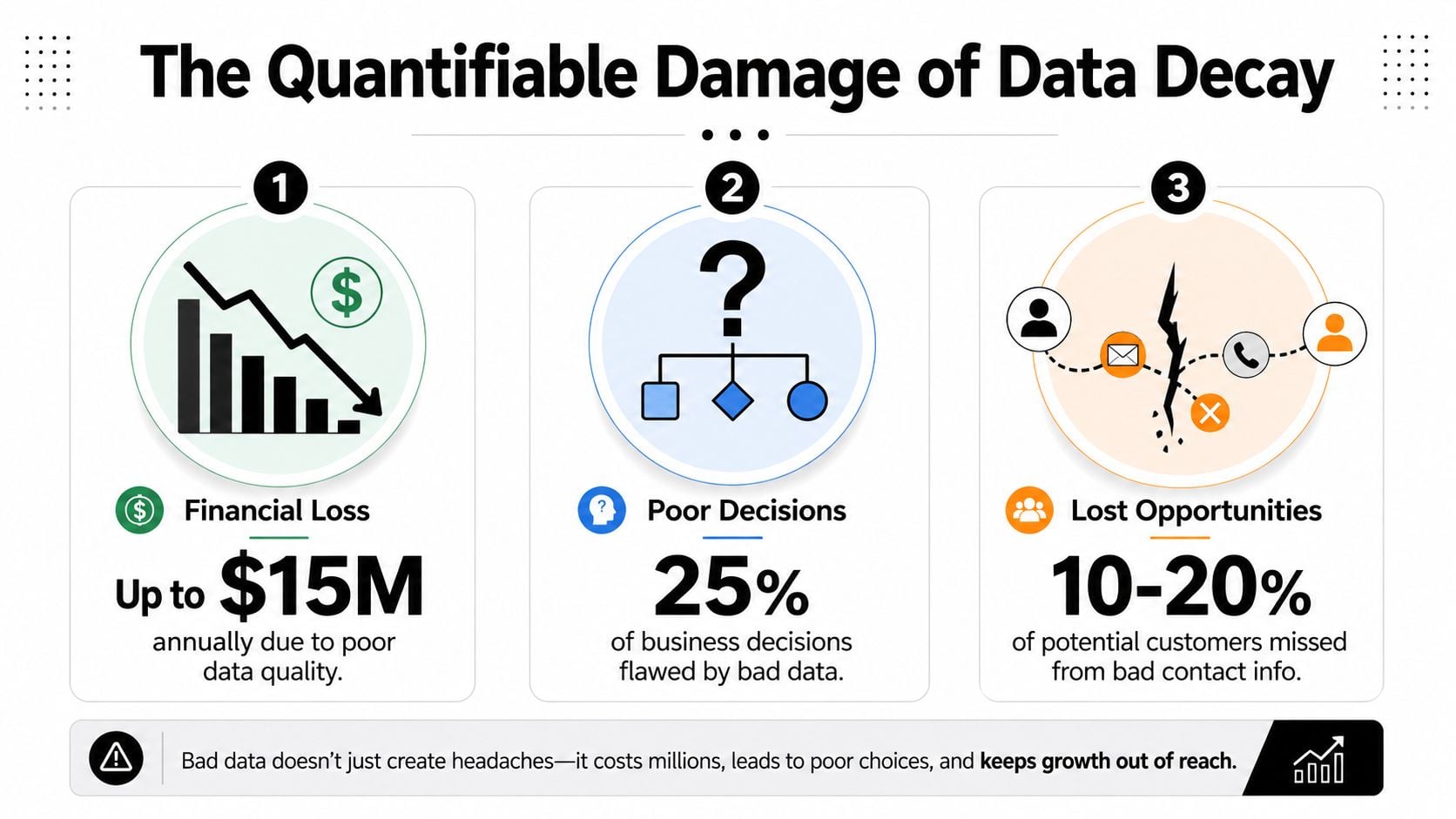
Los pequeños problemas de lista se convierten en grandes fugas financieras
El correo electrónico hace que el costo sea visible rápidamente. Si el 10% de una lista de 100,000 contactos no es válido y aún así paga para adquirir o enviar mensajes a esos contactos, el presupuesto ya se está quemando antes de que la campaña tenga la oportunidad de funcionar. Luego viene el costo de segundo orden. Las tasas de rebote más altas perjudican la colocación en la bandeja de entrada, lo que reduce el valor de las direcciones válidas que aún tiene.
Por eso los equipos de entregabilidad observan la tasa de rebote como una métrica de ganancia, no solo como una métrica de correo electrónico. Una explicación práctica de por qué las tasas de rebote importan para el éxito de la campaña muestra cómo el deterioro de la lista se convierte en problemas de reputación del remitente que afectan a futuros envíos, no solo al actual.
He visto esto desarrollarse en revisiones trimestrales. Marketing reporta un problema creativo u oferta. El problema subyacente es la calidad de la lista. El equipo sigue optimizando el texto mientras los proveedores de buzones siguen reduciendo la colocación en la bandeja de entrada.
La solución comienza con mejores entradas. Los equipos que verifican direcciones antes del lanzamiento y entre campañas pueden garantizar la calidad de la lista de marketing y dejar de pagar por enviar mensajes que nunca fueron entregables.
Los registros deficientes distorsionan las decisiones después de que termina la campaña
El costo mayor a menudo aparece después del envío. Los datos sucios corrompen la atribución, las definiciones de audiencia y el informe de rendimiento. Si los registros duplicados dividen el historial de participación en dos perfiles, un cliente puede parecer dos clientes potenciales débiles en lugar de un comprador calificado. Si el estado del ciclo de vida o el consentimiento está obsoleto, la audiencia equivocada se cuenta en la cohorte equivocada. Eso cambia las decisiones de presupuesto.
Gartner ha estimado que la mala calidad de datos cuesta a las organizaciones un promedio de $12.9 millones anuales, y esa cifra ayuda a explicar por qué los registros deficientes crean más que trabajo de limpieza técnica. Producen errores financieros a nivel de gestión, porque los equipos asignan gastos, personal y combinación de canales basados en informes en los que no deberían confiar (Gartner, citado aquí).
La experiencia del cliente también se ve afectada. Twilio Segment encontró que el 56% de los consumidores se convertirán en compradores repetidos después de una experiencia personalizada, lo que significa que la personalización inexacta conlleva una penalización directa en los ingresos cuando los datos subyacentes son incorrectos (Informe de personalización de Twilio Segment). Los contactos duplicados, las preferencias desactualizadas y los identificadores incorrectos conducen a mensajes repetidos, recomendaciones irrelevantes y errores obvios de CRM que señalan que la marca no está prestando atención.
Aquí está el patrón empresarial:
| Problema operacional | Efecto inmediato | Consecuencia empresarial |
|---|---|---|
| Direcciones de correo electrónico no válidas | Rebotes más altos | Presupuesto de envío desperdiciado y colocación más baja en la bandeja de entrada |
| Contactos duplicados | Historiales divididos y alcance repetido | Mala experiencia del cliente y atribución poco confiable |
| Campos CRM incorrectos | Segmentación defectuosa | Campañas mal dirigidas y oportunidad de conversión perdida |
| Consentimiento obsoleto o estado del cliente | Mensajería a la audiencia equivocada | Exposición de cumplimiento y daño de marca |
Algunos registros deficientes no permanecen pequeños. Se propagan a través de informes, automatización, orientación y puntos de contacto con el cliente hasta que un problema de higiene de datos se convierte en un problema de ingresos.
Un Marco Práctico para la Limpieza de Datos
Una vez que los equipos aceptan que la calidad de los datos afecta los ingresos, el siguiente problema es la priorización. La mayoría de las bases de datos contienen demasiados problemas para limpiar todos a la vez. La jugada correcta no es perseguir datos perfectos. Es arreglar los registros que tienen el mayor radio de impacto operativo.
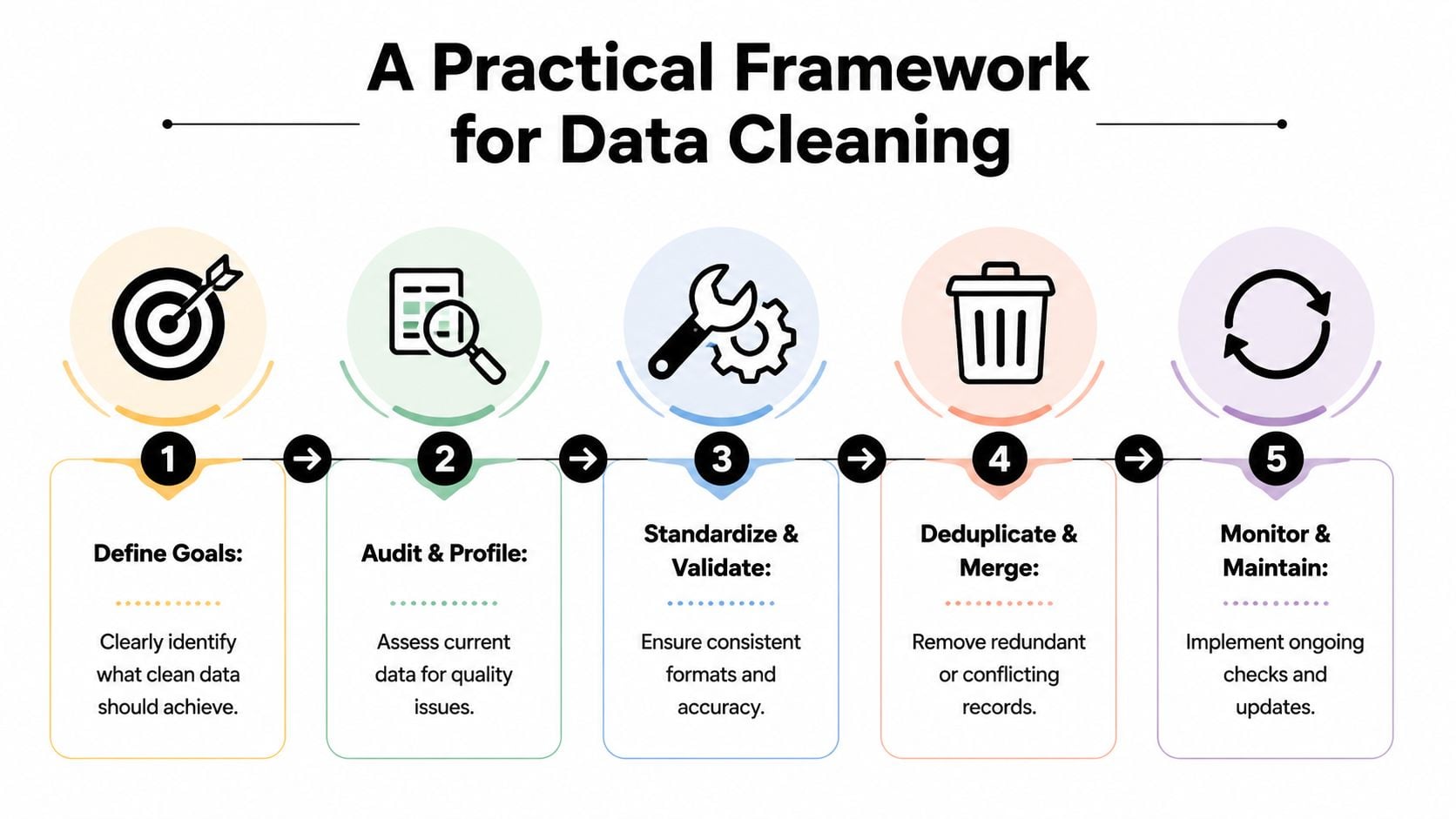
Comienza con el impacto empresarial, no con la perfección de los datos
Una secuencia útil se ve así:
Define el resultado empresarial
Decide qué datos limpios deben proteger o mejorar. Para marketing, podría ser entregabilidad de correo electrónico, precisión de segmentación o confiabilidad de atribución. Para ventas, podría ser eficiencia de enrutamiento y secuencia.Perfila el estado actual
Audita la base de datos para buscar duplicados, valores faltantes, formatos inconsistentes, correos electrónicos inválidos y registros obsoletos. Este paso debe producir categorías de falla, no solo una larga lista de errores.Estandariza lo que nunca debe variar
Normaliza campos como nombres, países, estados, formatos de teléfono, etapas del ciclo de vida y valores de origen. La estandarización elimina la ambigüedad antes de intentar analizar o automatizar.Desduplicar y fusionar cuidadosamente
No solo elimines duplicados sospechosos. Decide cuál es el registro del sistema de registro y cómo se deben fusionar el compromiso, la propiedad y el historial de consentimiento.Valida campos de alto riesgo antes de usar
Los campos orientados al cliente merecen controles más estrictos que los metadatos de bajo impacto. Las direcciones de correo electrónico, los indicadores de consentimiento y los campos de personalización deben validarse antes de que activen campañas.
Aquí es donde las herramientas entran en la conversación. Para equipos enfocados específicamente en datos de contacto, BillionVerify es un servicio profesional de verificación de correo electrónico construido para resolver un problema: los datos de correo electrónico deficientes cuestan dinero a las empresas.
Utiliza un modelo de priorización simple
Una matriz de impacto versus esfuerzo mantiene el trabajo práctico.
Alto impacto, bajo esfuerzo
La verificación de correo electrónico, la supresión de duplicados y la normalización de formato generalmente pertenecen aquí. Estas correcciones a menudo mejoran el desempeño de la campaña rápidamente.Alto impacto, alto esfuerzo
La resolución de identidad entre sistemas y la gobernanza de campos CRM encajan en esta categoría. Vale la pena hacerlo, pero necesitan propiedad y disciplina del proceso.Bajo impacto, bajo esfuerzo
La limpieza cosmética y el ordenamiento de etiquetas de campos pueden ocurrir más tarde a menos que bloqueen la generación de informes.Bajo impacto, alto esfuerzo
Evita estos al principio. Los equipos a menudo pierden tiempo limpiando campos heredados oscuros que no influyen en la actividad de ingresos.
Muchos equipos de operaciones de marketing cometen el error de comenzar con una limpieza amplia de CRM cuando deberían comenzar con los registros utilizados activamente en campañas. Si el archivo de correo electrónico está sucio, nada más recibe una prueba justa. Esa es una razón por la cual la orientación práctica de mantenimiento de listas como lo que significa la limpieza de listas para el desempeño del correo electrónico es tan útil en la planificación operativa.
Construye controles antes de que la siguiente carga rompa las cosas nuevamente
La limpieza sin controles crea un ciclo de reelaboración. La base de datos se ve mejor durante una semana, luego la siguiente importación, formulario, sincronización o actualización manual reintroduce los mismos defectos.
Utiliza controles como:
- Validación de entrada para formularios e importaciones
- Reglas de campo para valores estándar
- Lógica de revisión de duplicados antes de la creación de registros
- Reglas de propiedad para quién puede editar campos sensibles
- Auditorías programadas para listas de campañas activas
El objetivo no es una limpieza única. Es una contaminación futura menor.
Resolviendo el Problema de Datos de Correo Electrónico con Verificación
El correo electrónico merece un trato separado porque un campo incorrecto puede crear una pérdida financiera inmediata. Un título de trabajo mal escrito puede sesgar los reportes. Una dirección de correo electrónico inválida o arriesgada desperdicia volumen de envío, aumenta el costo de adquisición, daña la entregabilidad de correo electrónico, y distorsiona los resultados de la campaña lo suficiente como para que los equipos tomen decisiones presupuestarias incorrectas.
Por qué el correo electrónico necesita verificación especializada
Las verificaciones de formato solo detectan los errores obvios. No confirman si un buzón puede recibir correo, si la dirección pertenece a un proveedor desechable, o si enviar a ella crea riesgo de reputación.
Esa distinción importa en programas de ingresos. Si un formulario de lead pagado acepta direcciones falsas o temporales, el problema no se queda solo en la base de datos. Marketing paga por adquirir registros inutilizables, ventas hace seguimiento de contactos muertos, y el reporte de campaña sobreestima el tamaño de la lista mientras subestima la verdadera tasa de conversión. He visto equipos culpar a la creatividad, la oferta y el timing cuando el problema subyacente era que demasiada parte del archivo nunca debería haber sido enviada.
Una herramienta de verificación como BillionVerify aborda esa brecha verificando señales de entregabilidad de correo electrónico en tiempo real e identificando direcciones de mayor riesgo antes de que afecten el desempeño. Si estás comparando enfoques entre proveedores y procesos, ayuda revisar cómo otros equipos garantizan la calidad de la lista de marketing antes de decidir qué nivel de verificación de correo electrónico necesitas.
Dónde encaja la verificación en el flujo de trabajo
La verificación tiene el mayor retorno en tres puntos operacionales:
En el punto de entrada
Valida direcciones durante el registro, captura de leads y envío de formularios para que registros malos no entren al CRM desde el principio.Antes de campañas importantes Verifica la lista de envío activa antes de lanzamientos de productos, promociones y envíos de reenganche. Los equipos generalmente recuperan el volumen desperdiciado más rápido durante esta actividad.
En un cronograma recurrente de higiene
Los datos de correo electrónico se degradan. La verificación debe estar dentro del mantenimiento de listas rutinario para que el archivo no vuelva a caer en el mismo patrón de falla.
Los equipos que quieren la mecánica práctica deberían comenzar con una explicación clara de cómo funciona la verificación de correo electrónico en la práctica. Una vez que el proceso es claro, se vuelve mucho más fácil colocar la verificación de correo electrónico en formularios, sincronizaciones de CRM y verificaciones previas al envío sin ralentizar la ejecución.
Midiendo el ROI de Datos Limpios
La mala calidad de los datos cuesta a las organizaciones un promedio de $12.9 millones por año, según Gartner. Por eso, las conversaciones sobre ROI alrededor de la limpieza de datos funcionan mejor cuando comienzan en términos financieros, no técnicos.
Un modelo simple es suficiente para iniciar una discusión seria:
ROI = (Valor Obtenido + Costo Evitado) / Costo de Inversión
Uso esta estructura porque refleja cómo los datos deficientes impactan el P&L de marketing. Algunas pérdidas aparecen como ingresos perdidos. Otras se sitúan en gastos desperdiciados, retrabajo manual, riesgo de cumplimiento normativo y toma de decisiones más lenta.
Una forma práctica de construir el caso de negocio
Comienza con elementos de línea que un director de marketing ya posee o puede influir:
- Gastos de campaña desperdiciados por enviar a registros que nunca se convertirán
- Ingresos perdidos por entregabilidad de correo electrónico más débil, segmentación deficiente o personalización rota
- Horas de operaciones y analista gastadas en corregir errores de campo prevenibles, duplicados y uniones incorrectas
- Riesgo de cumplimiento normativo vinculado a registros de consentimiento débiles e higiene de CRM inconsistente
- Costos de marca y confianza del cliente cuando la persona equivocada recibe el mensaje equivocado, más de una vez
El error que veo en las solicitudes de presupuesto es que los equipos solo cuentan las ganancias. Los líderes financieros también quieren ver qué deja de perder la empresa. Esto incluye la exposición creada por controles de retención deficientes, estado de consentimiento inexacto e historiales de contacto incompletos. Como se señaló anteriormente, los problemas de calidad de datos no se quedan dentro del equipo de operaciones. Afectan la eficiencia de la campaña, la confianza en la información y la preparación para auditorías al mismo tiempo.
Perspectiva del caso de negocio: Posiciona la limpieza de datos como una iniciativa de protección de ingresos y mejora de margen. Este enfoque generalmente obtiene tracción más rápida que un argumento genérico de calidad.
Separa las ganancias de la pérdida evitada
Los modelos de ROI más limpios usan dos categorías.
Valor obtenido cubre la mejora de rendimiento medible: más mensajes llegando a destinatarios reales, mejor conversión de segmentos de audiencia más limpios e informes en los que puede confiar al cambiar el gasto entre canales o campañas.
Costo evitado cubre las pérdidas que desaparecen: menos envíos desperdiciados, menos horas gastadas en reparar registros manualmente, menos riesgo de problemas de cumplimiento normativo evitables y menos daño a la reputación del remitente que puede afectar el rendimiento de futuras campañas.
Mantén la estimación fundamentada en flujos de trabajo que tu equipo controla. Si el correo electrónico es el flujo de datos de cliente de mayor volumen, comienza allí. Un equipo de marketing no necesita un modelo de datos maestro de toda la empresa para justificar la acción. Necesita una estimación defendible del gasto recuperado, ingresos protegidos y retrabajo reducido. Para equipos que construyen ese modelo, esta guía sobre calcular el ROI de verificación de correo electrónico proporciona una estructura de planificación útil.
De una corrección única a una estrategia proactiva de datos
Las empresas que manejan bien los datos no esperan a un problema del panel de control o un incidente de entregabilidad de correo electrónico para actuar. Construyen rutinas que evitan que registros deficientes entren en sistemas críticos desde el principio.
Eso generalmente significa que tres hábitos se vuelven estándar. Primero, validar datos en el punto de captura, especialmente para formularios orientados al cliente y listas de campaña. Segundo, ejecutar auditorías recurrentes en los registros que alimentan el alcance activo y los informes. Tercero, definir la propiedad para que las personas sepan quién puede cambiar campos, fusionar registros y aprobar importaciones.
También hay un cambio de mentalidad estratégica aquí. Los datos limpios no son el estado final. Es una disciplina de mantenimiento. Los registros cambian, los contactos se pierden, las bandejas de entrada caducan y los traspases entre plataformas crean nuevas inconsistencias. Los equipos que tratan la limpieza como un proyecto único terminan pagando dos veces por los mismos errores.
Los sistemas limpios no permanecen limpios por accidente. Alguien establece las reglas, alguien monitorea las excepciones y alguien arregla las causas raíz en lugar de limpiar síntomas repetidamente.
Para los líderes de marketing, esa disciplina se convierte en una ventaja competitiva. Las campañas se lanzan con menos sorpresas. Los informes se vuelven más fáciles de confiar. Las ventas dedican menos tiempo a cuestionar la calidad del cliente potencial. Las revisiones de cumplimiento se vuelven menos dolorosas. Y el rendimiento del correo electrónico refleja la estrategia con mayor precisión porque la lista no está trabajando en contra de la campaña.
Si los datos de correo electrónico son una de las mayores fuentes de desperdicio en tu embudo, BillionVerify vale la pena evaluar como parte de un programa de higiene más amplio. Se ajusta a la necesidad práctica que muchas organizaciones enfrentan: verificar direcciones antes de enviar, detectar entradas desechables y riesgosas temprano, y reducir la fricción operativa que crean los datos de correo electrónico deficientes.