


A qualidade deficiente dos dados pode consumir uma parcela significativa da receita. A IBM relata que a qualidade deficiente dos dados custa à economia dos EUA $3,1 trilhões por ano (estimativa da IBM sobre o custo de dados ruins). Para um diretor de marketing, esse não é um problema abstrato de governança de dados. Aparece como mídia paga enviada para contatos inválidos, tempo de vendas desperdiçado em leads ruins, segmentação mais fraca e relatórios de atribuição que fazem campanhas saudáveis parecerem quebradas.
Tenho visto o mesmo padrão em equipes de geração de demanda. Uma lista pode parecer grande o suficiente para atingir objetivos de pipeline enquanto esconde registros duplicados, emails desatualizados e erros de formatação que reduzem taxas de resposta e aumentam custos de aquisição. O email geralmente é o lugar mais rápido para ver a perda, e é por isso que listas de email limpas são importantes para o desempenho da campanha e reputação do remetente.
A questão comercial é simples. Qual é o custo de deixar registros ruins em vigor por mais um trimestre?
Esse custo se concentra em dois lugares. Primeiro, há desperdício direto: envios extras, custos de plataforma mais altos, conversão mais baixa de campanhas mal direcionadas e horas de SDR gastas com registros que nunca deveriam ter entrado no sistema. Segundo, há dano subsequente à tomada de decisões. Se a fonte de leads, campos firmográficos ou histórico de engajamento estiverem errados, a equipe financia os canais errados e corta os certos. É por isso que programas de dados fortes começam com impacto comercial, não com perfeição de banco de dados, um ponto reforçado por insights de qualidade de dados do Orbit AI.
A limpeza de dados ganha orçamento quando as equipes a tratam como proteção de receita com ROI mensurável, não como manutenção rotineira.
Limpeza de Dados é uma Estratégia de Receita, Não uma Tarefa de TI
Muitas organizações ainda falam sobre limpeza de dados como se fosse trabalho administrativo. Isso é um erro. Quando equipes de receita enviam para contatos inválidos, personalizam a partir de registros danificados ou segmentam por campos desatualizados, elas não estão lidando com um incômodo técnico. Estão financiando o baixo desempenho.
A importância da limpeza de dados tem menos a ver com bancos de dados bem organizados e mais com a qualidade da execução. O Marketing pode produzir conteúdo criativo forte, ofertas inteligentes e planejamento de campanha disciplinado, depois perder desempenho porque o arquivo de público está errado no momento do envio. As Vendas podem trabalhar em um território promissor, depois descobrir que o CRM está repleto de duplicatas, funções desatualizadas e endereços de email inválidos. As equipes de Produto podem estudar o comportamento de inscrição, depois basear decisões em dados deficientes.
Muito do pensamento operacional mais forte nesta área agora trata a higiene de dados como um sistema de negócios, não como uma limpeza única. A estrutura em análises de qualidade de dados da Orbit AI é útil porque conecta a qualidade dos dados à confiabilidade operacional, em vez de tratá-la como uma tarefa isolada de banco de dados.
Regra prática: Se um campo influencia segmentação, personalização, roteamento ou relatórios, não é um campo de TI. É um campo de receita.
Essa mudança de mentalidade é importante porque dados de contato ruins tendem a se esconder atrás de métricas de canal. As equipes culpam as linhas de assunto, a qualidade da oferta ou a velocidade de acompanhamento de vendas quando a lista em si é o problema. Em programas de email especialmente, a qualidade da lista determina se a campanha tem uma chance justa. É por isso que muitas equipes começam a reforçar a higiene da lista e revisar recursos como por que listas de email limpas são importantes antes de mudarem sua estratégia.
A Anatomia de Dados Sujos
Dados sujos criam risco operacional muito antes de alguém classificá-los como um problema de qualidade de dados. Na prática, aparecem como uma campanha paga enviada para caixas de entrada inválidas, leads roteados para o representante errado, contatos duplicados inflacionando contagens de pipeline, ou registros de consentimento que não correspondem mais ao que o marketing pode enviar.
Dentro de CRMs, ESPs, formulários de inscrição, ferramentas de enriquecimento e plataformas de BI, registros ruins raramente se anunciam. Parecem utilizáveis até que uma equipe tente segmentar, rotear, personalizar, relatar ou prever a partir deles. É por isso que dados sujos são caros. Falham no ponto de uso, depois que o orçamento, tempo e tomada de decisão já foram comprometidos.
Dados sujos aparecem em cinco formas familiares
Esses são os padrões de falha que criam a maior parte do arrasto operacional:
Registros incompletos
Campos ausentes quebram regras de segmentação, pontuação de leads, lógica de roteamento e personalização. Um contato sem um email válido, região ou estágio de ciclo de vida pode ficar no banco de dados por meses e ainda ser inutilizável quando a campanha entra em operação.Entradas inexatas
Erros de digitação, entradas falsas, endereços malformados e detalhes firmográficos incorretos criam falsa confiança. O registro existe, mas a equipe não pode confiar nele.Registros duplicados
Duplicatas dividem histórico de engajamento, atribuição e propriedade. O marketing pode suprimir um registro e enviar o outro. O departamento de vendas pode ligar para o mesmo comprador duas vezes. O relatório então conta atividade em dois perfis e apresenta incorretamente o desempenho.Formatação inconsistente
O mesmo nome da empresa, país ou função de trabalho aparece em vários formatos. A filtragem se torna pouco confiável, as regras de correspondência perdem sobreposições óbvias e as equipes começam a corrigir relatórios manualmente em planilhas.Dados desatualizados
As pessoas mudam de emprego, departamentos se mesclam, as caixas de entrada ficam inativas e o status de consentimento muda ao longo do tempo. A degradação de dados é normal. O erro operacional é tratar o registro válido de ontem como o registro seguro de hoje.
Para equipes de email, essas questões geralmente convergem em uma lista. Um arquivo único pode conter caixas de entrada abandonadas, contas de função, domínios catch-all, duplicatas e erros de formatação ao mesmo tempo. Uma explicação prática de o que a limpeza de lista envolve para o desempenho do email ajuda a esclarecer por que "remover alguns contatos ruins" é uma visão muito estreita do problema.
A limpeza também é confundida com coleta. São trabalhos diferentes. Adicionar mais registros a um sistema quebrado geralmente aumenta o volume de erros, porque as mesmas regras de validação fraca, padrões de campo e problemas de sincronização continuam produzindo novas entradas ruins.
O processo em si é bem estabelecido. A visão geral técnica na referência do fluxo de trabalho de limpeza de dados descreve etapas principais como remover duplicatas, lidar com valores ausentes, padronizar formatos, validar completude e verificar precisão antes da análise ou ativação. Esse trabalho situa-se a montante da qualidade de relatórios, qualidade de automação e qualidade de modelo.
O princípio de lixo entra, lixo sai é uma descrição literal do que acontece nas operações. Os relatórios refletem entradas ruins. As automações disparam nas condições erradas. Os modelos aprendem com registros que nunca deveriam ter chegado aos sistemas de produção.
O Dano Quantificável da Deterioração de Dados
A má qualidade dos dados custa às organizações uma média de $12,9 milhões por ano, de acordo com a IBM. Esse número de manchete chama atenção, mas o dano operacional é mais fácil de ser negligenciado porque aparece em dezenas de itens de linha: gastos com mídia desperdiçados, taxas de conversão mais baixas, previsões ruins e experiências de cliente que parecem negligentes em vez de coordenadas (IBM via Experian).
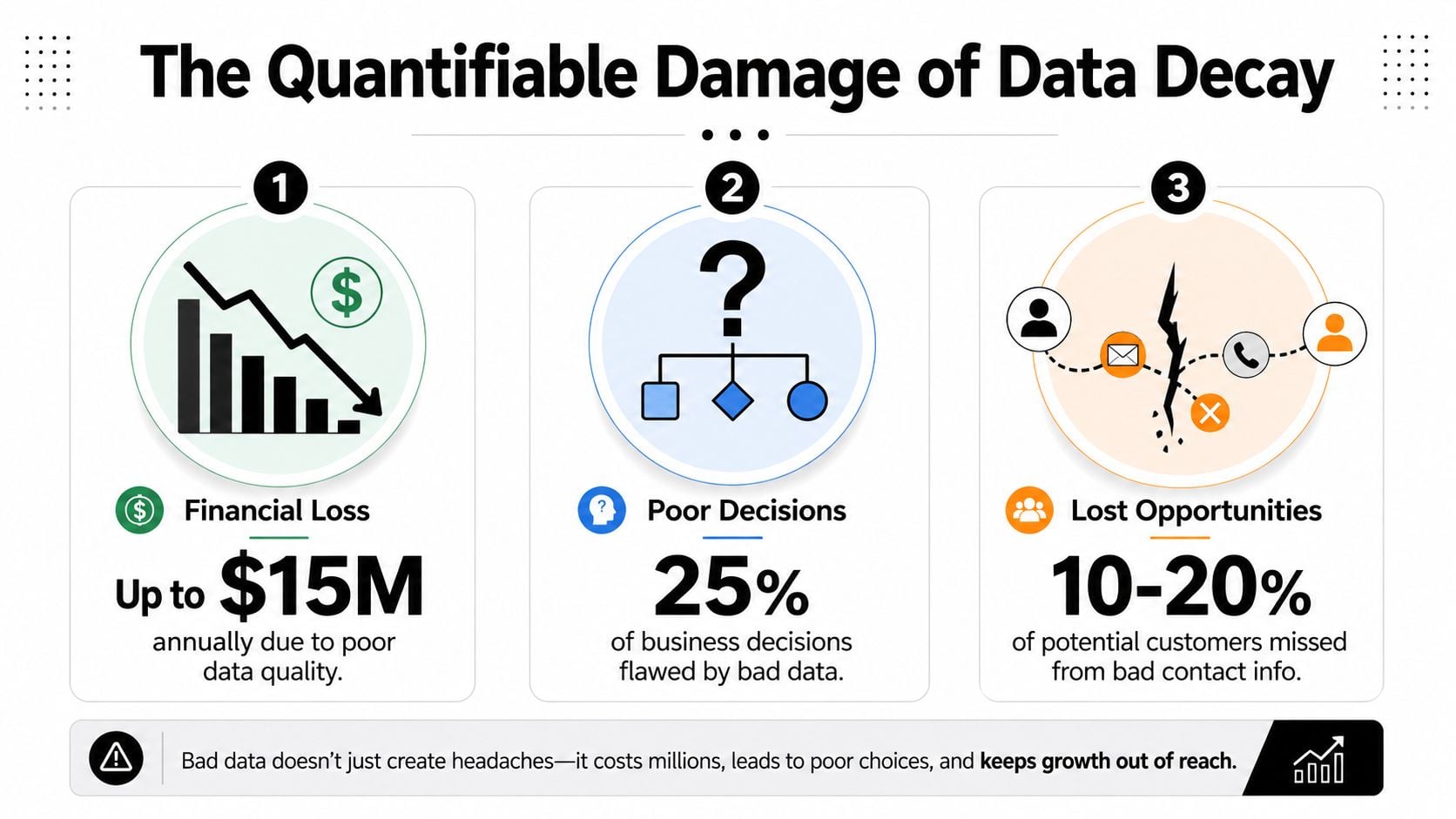
Pequenos problemas de lista se tornam grandes vazamentos financeiros
O email torna o custo visível rapidamente. Se 10% de uma lista de 100.000 contatos é inválida e você paga para adquirir ou enviar mensagens para esses contatos de qualquer forma, o orçamento já está sendo queimado antes de a campanha ter a chance de se desempenhar. Então vem o custo de segunda ordem. Taxas de rejeição mais altas prejudicam o posicionamento na caixa de entrada, o que reduz o valor dos endereços válidos que você ainda tem.
É por isso que as equipes de entregabilidade monitoram a taxa de rejeição como uma métrica de lucro, não apenas uma métrica de email. Uma explicação prática de por que as taxas de rejeição importam para o sucesso da campanha mostra como a deterioração da lista se transforma em problemas de reputação do remetente que afetam envios futuros, não apenas o atual.
Eu vi isso acontecer em revisões trimestrais. O marketing relata um problema criativo ou de oferta. O problema subjacente é a qualidade da lista. A equipe continua otimizando cópia enquanto os provedores de caixa de correio continuam reduzindo o posicionamento na caixa de entrada.
A solução começa com entradas melhores. As equipes que verificam endereços antes do lançamento e entre campanhas podem garantir a qualidade da lista de marketing e parar de pagar para enviar mensagens que nunca foram entregáveis.
Registros ruins distorcem decisões após o fim da campanha
O custo maior geralmente aparece após o envio. Dados sujos corrompem atribuição, definições de público e relatórios de desempenho. Se registros duplicados dividirem o histórico de engajamento em dois perfis, um cliente pode parecer dois leads fracos em vez de um comprador qualificado. Se o estágio do ciclo de vida ou o status de consentimento estiver desatualizado, o público errado é contado na coorte errada. Isso muda as decisões de orçamento.
A Gartner estimou que a má qualidade dos dados custa às organizações uma média de $12,9 milhões anualmente, e esse número ajuda a explicar por que registros ruins criam mais do que apenas trabalho técnico de limpeza. Eles produzem erros financeiros em nível de gestão, porque as equipes alocam gastos, número de funcionários e mix de canais com base em relatórios nos quais não devem confiar (Gartner, citado aqui).
A experiência do cliente também sofre. Twilio Segment descobriu que 56% dos consumidores se tornarão compradores repetidos após uma experiência personalizada, o que significa que a personalização imprecisa acarreta uma penalidade de receita direta quando os dados subjacentes estão errados (relatório de personalização Twilio Segment). Contatos duplicados, preferências desatualizadas e identificadores incorretos levam a mensagens repetidas, recomendações irrelevantes e erros óbvios de CRM que sinalizam que a marca não está prestando atenção.
Aqui está o padrão de negócio:
| Problema operacional | Efeito imediato | Consequência de negócio |
|---|---|---|
| Endereços de email inválidos | Rejeições mais altas | Orçamento de envio desperdiçado e menor posicionamento na caixa de entrada |
| Contatos duplicados | Históricos divididos e alcance repetido | Experiência do cliente ruim e atribuição não confiável |
| Campos CRM incorretos | Segmentação deficiente | Campanhas mal direcionadas e oportunidade de conversão perdida |
| Consentimento desatualizado ou status do cliente | Mensagens para o público errado | Exposição de conformidade e dano à marca |
Alguns registros ruins não permanecem pequenos. Eles se espalham por relatórios, automação, direcionamento e pontos de contato com o cliente até que um problema de higiene de dados se torne um problema de receita.
Um Framework Prático para Limpeza de Dados
Quando as equipes aceitam que a qualidade dos dados afeta a receita, o próximo problema é a priorização. A maioria dos bancos de dados contém muitos problemas para limpar de uma vez. A jogada certa não é perseguir dados perfeitos. É corrigir os registros que têm o maior raio de blast operacional.
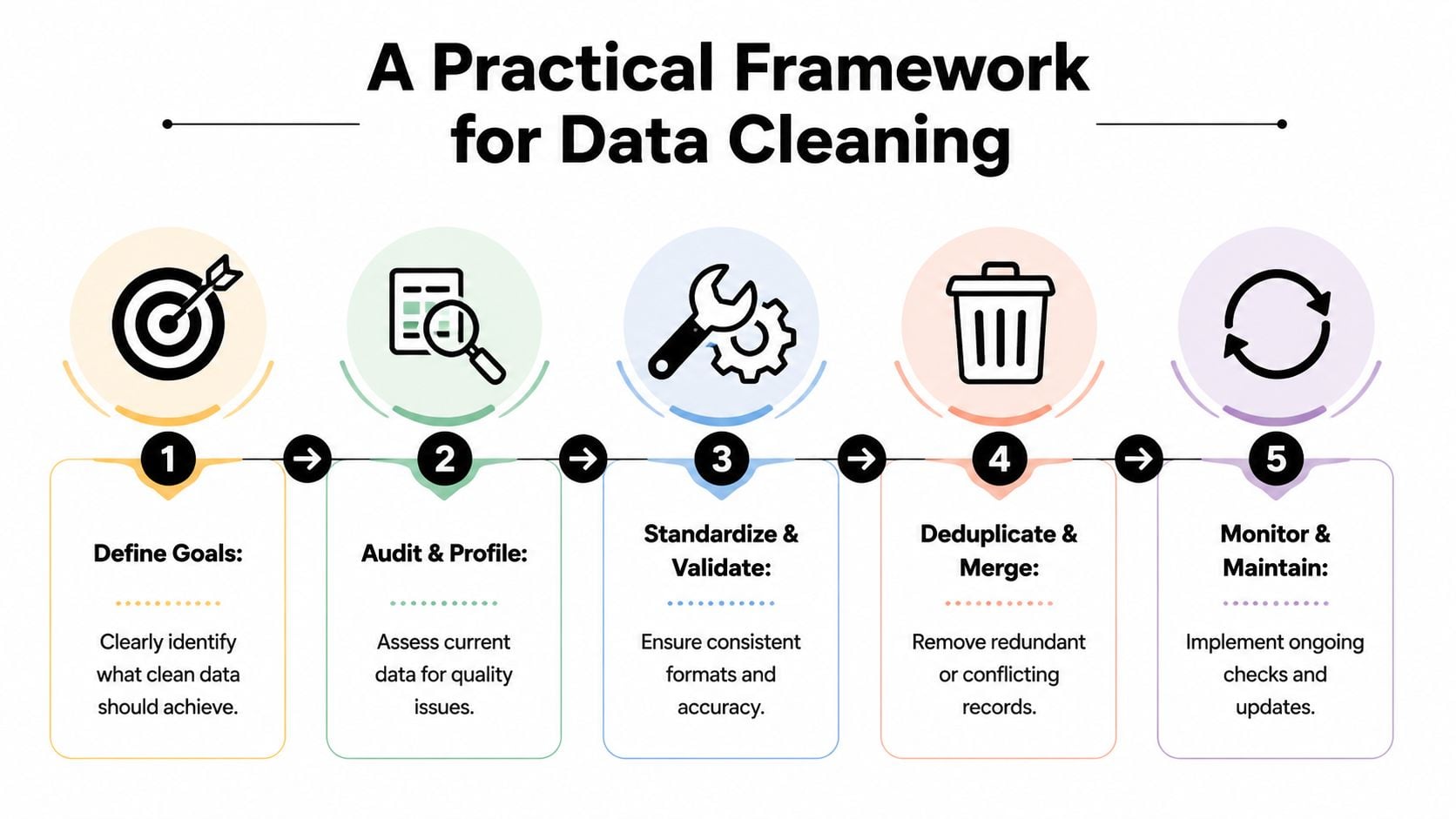
Comece com impacto comercial, não com perfeição de dados
Uma sequência útil é assim:
Defina o resultado comercial
Decida o que os dados limpos devem proteger ou melhorar. Para marketing, pode ser entregabilidade, precisão de segmentação ou confiabilidade de atribuição. Para vendas, pode ser eficiência de roteamento e sequência.Perfil do estado atual
Audite o banco de dados quanto a duplicatas, valores ausentes, formatos inconsistentes, e-mails inválidos e registros obsoletos. Esta etapa deve produzir categorias de falha, não apenas uma longa lista de erros.Padronize o que nunca deve variar
Normalize campos como nomes, países, estados, formatos de telefone, estágios do ciclo de vida e valores de origem. A padronização remove a ambiguidade antes de tentar analisar ou automatizar.Deduplicar e mesclar com cuidado
Não apenas delete duplicatas suspeitas. Decida qual registro é o sistema de registro e como o histórico de engajamento, propriedade e consentimento deve ser mesclado.Valide campos de alto risco antes do uso
Campos voltados para o cliente merecem verificações mais rigorosas do que metadados de baixo impacto. Endereços de e-mail, indicadores de consentimento e campos de personalização devem ser validados antes de acionarem campanhas.
É também aqui que as ferramentas entram na conversa. Para equipes focadas especificamente em dados de contato, BillionVerify é um serviço profissional de verificação de e-mail construído para resolver um problema: dados de e-mail ruins custam dinheiro às empresas.
Use um modelo de priorização simples
Uma matriz de impacto versus esforço mantém o trabalho prático.
Alto impacto, baixo esforço
Validação de e-mail, supressão de duplicatas e normalização de formatação geralmente pertencem aqui. Essas correções geralmente melhoram o desempenho da campanha rapidamente.Alto impacto, alto esforço
Resolução de identidade entre sistemas e governança de campos CRM se encaixam nesta categoria. Eles valem a pena, mas precisam de propriedade e disciplina de processo.Baixo impacto, baixo esforço
Limpeza cosmética e arrumação de rótulos de campo podem acontecer depois, a menos que bloqueiem relatórios.Baixo impacto, alto esforço
Evite isso no início. As equipes frequentemente perdem tempo limpando campos legados obscuros que não influenciam a atividade de receita.
Muitas equipes de marketing ops cometem o erro de começar com limpeza ampla de CRM quando deveriam começar com registros ativamente usados em campanhas. Se o arquivo de e-mail está sujo, nada mais recebe um teste justo. Essa é uma razão pela qual orientação prática de manutenção de listas como o que limpeza de listas significa para desempenho de e-mail é tão útil no planejamento operacional.
Crie controles antes que o próximo upload quebre as coisas novamente
Limpeza sem controles cria um loop de retrabalho. O banco de dados parece melhor por uma semana, depois a próxima importação, formulário, sincronização ou atualização manual reintroduz os mesmos defeitos.
Use controles como:
- Validação de entrada para formulários e importações
- Regras de campo para valores padrão
- Lógica de revisão de duplicatas antes da criação de registro
- Regras de propriedade para quem pode editar campos sensíveis
- Auditorias agendadas para listas de campanhas ativas
O objetivo não é uma limpeza única. É menor contaminação futura.
Resolvendo o Problema de Dados de Email com Verificação
Email merece tratamento separado porque um campo inválido pode criar uma perda financeira imediata. Um título de cargo digitado incorretamente pode distorcer relatórios. Um endereço de email inválido ou arriscado desperdiça volume de envio, aumenta o custo de aquisição, prejudica a entregabilidade e distorce os resultados da campanha o suficiente para que as equipes tomem decisões orçamentárias erradas.
Por que o email precisa de verificação especializada
Verificações de formato capturam apenas erros óbvios. Elas não confirmam se uma caixa de correio pode receber email, se o endereço pertence a um provedor descartável ou se o envio para ele cria risco de reputação.
Essa distinção é importante em programas de receita. Se um formulário de lead pago aceita endereços falsos ou temporários, o problema não fica apenas no banco de dados. Marketing paga para adquirir registros inutilizáveis, vendas faz acompanhamento de contatos inativos, e os relatórios de campanha superestimam o tamanho da lista enquanto subestimam a taxa de conversão verdadeira. Já vi equipes culparem criatividade, oferta e tempo quando o problema subjacente era que muito do arquivo nunca deveria ter sido enviado.
Uma ferramenta de verificação como BillionVerify resolve essa lacuna verificando sinais de entregabilidade em tempo real e sinalizando endereços de maior risco antes que afetem o desempenho. Se você está comparando abordagens entre fornecedores e processos, é útil revisar como outras equipes garantem a qualidade da lista de marketing antes de decidir qual nível de verificação você precisa.
Onde a verificação se encaixa no fluxo de trabalho
A verificação tem o maior retorno em três pontos operacionais:
No ponto de entrada
Valide endereços durante inscrição, captura de leads e envio de formulário para que registros ruins não entrem no CRM em primeiro lugar.Antes de grandes campanhas
Verifique a lista de envio ativa antes de lançamentos de produtos, promoções e envios de reengajamento. As equipes geralmente recuperam volume desperdiçado mais rapidamente durante essa atividade.Em um cronograma de higiene recorrente
Os dados de email se degradam. A verificação deve fazer parte da manutenção rotineira da lista para que o arquivo não retorne ao mesmo padrão de falha.
As equipes que desejam compreender a mecânica prática devem começar com uma explicação clara de como a verificação de email funciona na prática. Quando o processo fica claro, fica muito mais fácil colocar verificação em formulários, sincronizações de CRM e verificações pré-envio sem desacelerar a execução.
Medindo o ROI de Dados Limpos
A má qualidade dos dados custa em média $12,9 milhões por ano às organizações, de acordo com Gartner. É por isso que as conversas sobre ROI em relação à limpeza funcionam melhor quando começam em termos financeiros, não técnicos.
Um modelo simples é suficiente para iniciar uma discussão séria:
ROI = (Valor Ganho + Custo Evitado) / Custo do Investimento
Uso esta estrutura porque reflete como dados ruins afetam o P&L de marketing. Algumas perdas aparecem como receita perdida. Outras se acumulam em gastos desperdiçados, retrabalho manual, risco de conformidade e tomada de decisão mais lenta.
Uma maneira prática de construir o caso de negócio
Comece com itens que um diretor de marketing já possui ou pode influenciar:
- Gastos de campanha desperdiçados ao enviar para registros que nunca se converterão
- Receita perdida por entrega mais fraca, segmentação deficiente ou personalização quebrada
- Horas de operações e analistas gastas corrigindo erros de campo evitáveis, duplicatas e uniões ruins
- Risco de conformidade ligado a registros de consentimento fracos e higiene de CRM inconsistente
- Custos de marca e confiança do cliente quando a pessoa errada recebe a mensagem errada, mais de uma vez
O erro que vejo nos pedidos de orçamento é que as equipes só contam com o lado positivo. Os líderes de finanças também querem ver o que a empresa deixa de perder. Isso inclui a exposição criada por controles de retenção deficientes, status de consentimento impreciso e históricos de contato incompletos. Como observado anteriormente, os problemas de qualidade dos dados não ficam apenas na equipe de operações. Eles afetam a eficiência da campanha, a confiança na apresentação de relatórios e a prontidão de auditoria ao mesmo tempo.
Perspectiva de caso de negócio: Posicione a limpeza de dados como uma iniciativa de proteção de receita e melhoria de margem. Esse enquadramento geralmente recebe mais tração do que um argumento de qualidade genérico.
Separe ganho de perda evitada
Os modelos de ROI mais limpos usam dois buckets.
Valor ganho cobre melhorias mensuráveis de desempenho: mais mensagens chegando aos destinatários reais, melhor conversão de segmentos de público mais limpos e relatórios em que você pode confiar ao mudar gastos entre canais ou campanhas.
Custo evitado cobre as perdas que desaparecem: menos envios desperdiçados, menos horas gastas reparando registros manualmente, menor risco de problemas de conformidade evitáveis e menos danos à reputação do remetente que podem reduzir o desempenho futuro da campanha.
Mantenha a estimativa fundamentada em fluxos de trabalho que sua equipe controla. Se o email for o fluxo de dados do cliente com maior volume, comece por lá. Uma equipe de marketing não precisa de um modelo de dados mestre em toda a empresa para justificar uma ação. Ela precisa de uma estimativa defensável de gastos recuperados, receita protegida e retrabalho reduzido. Para equipes que constroem esse modelo, este guia para calcular o ROI de verificação de email oferece uma estrutura de planejamento útil.
De Uma Correção Única para Uma Estratégia Proativa de Dados
As empresas que lidam bem com dados não esperam por um problema no painel ou um incidente de entrega para agir. Elas estabelecem rotinas que impedem que registros ruins entrem em sistemas críticos desde o início.
Isso geralmente significa que três hábitos se tornam padrão. Primeiro, validar dados no ponto de captura, especialmente para formulários voltados para o cliente e listas de campanhas. Segundo, executar auditorias recorrentes nos registros que alimentam o alcance ativo e relatórios. Terceiro, definir a propriedade para que as pessoas saibam quem pode alterar campos, mesclar registros e aprovar importações.
Há também uma mudança estratégica de mentalidade aqui. Dados limpos não são o estado final. É uma disciplina de manutenção. Registros mudam, contatos são perdidos, caixas de entrada expiram, e transferências entre plataformas criam novas inconsistências. Equipes que tratam a limpeza como um projeto único acabam pagando pelos mesmos erros duas vezes.
Sistemas limpos não permanecem limpos por acaso. Alguém define as regras, alguém monitora as exceções, e alguém corrige as causas raiz em vez de limpar repetidamente os sintomas.
Para líderes de marketing, essa disciplina se torna uma vantagem competitiva. As campanhas são lançadas com menos surpresas. Os relatórios se tornam mais fáceis de confiar. O Sales gasta menos tempo questionando a qualidade dos leads. As revisões de conformidade se tornam menos dolorosas. E o desempenho do email reflete a estratégia com mais precisão porque a lista não está funcionando contra a campanha.
Se os dados de email são uma das maiores fontes de desperdício em seu funil, BillionVerify vale a pena avaliar como parte de um programa de higiene mais amplo. Ele atende à necessidade prática que muitas organizações enfrentam: verificar endereços antes de envios, capturar entradas descartáveis e arriscadas no início, e reduzir o arrasto operacional que dados de email ruins criam.