


Niska jakość danych może pochłonąć znaczną część przychodu. IBM informuje, że niska jakość danych kosztuje gospodarkę USA 3,1 biliona dolarów rocznie (oszacowanie IBM kosztów złych danych). Dla dyrektora marketingu nie jest to abstrakcyjny problem zarządzania danymi. Objawia się to jako media płatne wysłane do nieprawidłowych kontaktów, czas sprzedaży zmarnowany na złych leadach, słabsza segmentacja i raporty atrybuji, które sprawiają, że zdrowe kampanie wyglądają na zepsute.
Widziałem ten sam wzorzec w zespołach generowania popytu. Lista może wyglądać na wystarczająco dużą, aby osiągnąć cele przychodu, jednocześnie ukrywając zduplikowane rekordy, nieświeże e-maile i błędy formatowania, które zmniejszają wskaźniki odpowiedzi i zwiększają koszty akwizycji. E-mail jest zwykle najszybszym miejscem, aby zobaczyć stratę, dlatego właśnie czyste listy e-mailowe mają znaczenie dla wydajności kampanii i reputacji nadawcy.
Pytanie biznesowe jest proste. Jaki jest koszt pozostawienia złych rekordów na kolejny kwartał?
Ten koszt rozkłada się w dwóch miejscach. Po pierwsze, istnieje bezpośrednia strata: dodatkowe wysłania, wyższe koszty platformy, niższa konwersja z niewłaściwie ukierunkowanych kampanii i godziny SDR spędzone na rekordach, które nigdy tam nie powinny trafić. Po drugie, istnieje uszkodzenie podejmowania decyzji w dalszym łańcuchu. Jeśli źródło leadów, pola firmograficzne lub historia zaangażowania są błędne, zespół finansuje złe kanały i porzuca właściwe. Dlatego silne programy danych zaczynają się od wpływu na biznes, a nie od doskonałości bazy danych, co potwierdza spostrzeżenia Orbit AI dotyczące jakości danych.
Czyszczenie danych uzyskuje budżet, gdy zespoły traktują je jako ochronę przychodów z mierzalnym zwrotem z inwestycji, a nie jako rutynową konserwację.
Czyszczenie danych to strategia przychodów, a nie zadanie IT
Wiele organizacji wciąż mówi o czyszczeniu danych, jakby to była praca administracyjna. To błąd. Kiedy zespoły przychodów wysyłają do nieprawidłowych kontaktów, personalizują dane z uszkodzonych rekordów lub segmentują na podstawie starych pól, nie mają do czynienia z uciążliwością techniczną. Finansują niedostateczne wyniki.
Powód, dla którego czyszczenie danych jest ważne, ma mniej wspólnego z schludnymi bazami danych, a więcej z jakością wykonania. Marketing może wytworzyć silną kreatywność, inteligentne oferty i zdyscyplinowane planowanie kampanii, a następnie stracić wydajność, ponieważ plik odbiorców jest błędny w momencie wysłania. Sprzedaż może pracować na obiecującym terenie, a następnie odkryć, że CRM jest pełny duplikatów, przestarzałych ról i złych adresów e-mail. Zespoły produktu mogą badać zachowanie podczas rejestracji, a następnie trenować decyzje na uszkodzonych danych wejściowych.
Wiele z najpotężniejszego myślenia operacyjnego w tej dziedzinie traktuje teraz higienę danych jako system biznesowy, a nie jednorazowe czyszczenie. Ujęcie w Orbit AI insights dotyczące jakości danych jest przydatne, ponieważ łączy jakość danych z niezawodnością operacyjną zamiast traktować ją jako izolowane zadanie bazy danych.
Reguła praktyczna: Jeśli pole wpływa na kierowanie, personalizację, routing lub raportowanie, nie jest to pole IT. To pole przychodów.
Ta zmiana mentalności ma znaczenie, ponieważ złe dane kontaktowe mają tendencję do ukrywania się za metrykami kanału. Zespoły obwiniają linie tematu, jakość oferty lub szybkość śledzenia sprzedaży, gdy problemem jest sama lista. Zwłaszcza w programach e-mail jakość listy określa, czy kampania w ogóle ma szansę powodzenia. Dlatego wiele zespołów zaczyna od zaostrzenia higieny listy i przeglądu zasobów takich jak dlaczego czyste listy e-mail mają znaczenie przed zmianą strategii.
Anatomia Brudnych Danych
Brudne dane tworzą ryzyko operacyjne długo zanim ktokolwiek oznaczy to problemem jakości danych. W praktyce pojawia się to jako płatna kampania wysłana na nieważne skrzynki pocztowe, leady kierowane do niewłaściwego reprezentanta, zduplikowane kontakty zawyżające liczbę potencjalnych klientów, lub rekordy zgody, które już nie odpowiadają temu, co marketing ma pozwolenie wysyłać.
Wewnątrz CRM, ESP, formularzy rejestracyjnych, narzędzi wzbogacania danych i platform BI, złe rekordy rzadko się ujawniają. Wyglądają użyteczne, dopóki zespół nie spróbuje ich segmentować, kierować, personalizować, raportować lub prognozować na ich podstawie. Dlatego brudne dane są kosztowne. Zawodzą w punkcie użycia, po tym jak budżet, czas i proces decyzyjny zostały już zaangażowane.
Brudne dane pojawiają się w pięciu znanych formach
To są wzorce awarii, które tworzą większość oporu operacyjnego:
Niekompletne rekordy
Brakujące pola niszczą reguły segmentacji, punktację leadów, logikę kierowania i personalizację. Kontakt bez ważnego e-maila, regionu lub etapu cyklu życia może pozostać w bazie danych przez miesiące i nadal być bezużyteczny, gdy kampania wejdzie na żywo.Niedokładne wpisy
Literówki, fałszywe dane wejściowe, zniekształcone adresy i nieprawidłowe szczegóły firmograficzne tworzą fałszywą pewność. Rekord istnieje, ale zespół nie może na nim polegać.Zduplikowane rekordy
Duplikaty fragmentują historię zaangażowania, atrybucję i odpowiedzialność. Marketing może wyłączyć jeden rekord i wysłać do drugiego. Dział sprzedaży może zadzwonić do tego samego kupującego dwa razy. Raportowanie następnie liczy aktywność na dwóch profilach i pokazuje błędne wyniki wydajności.Niespójne formatowanie
Nazwa firmy, kraj lub funkcja zawodowa pojawiają się w kilku formatach. Filtrowanie staje się zawodne, reguły dopasowania pomijają oczywiste nakładania się, a zespoły zaczynają ręcznie naprawiać raporty w arkuszach kalkulacyjnych.Nieaktualne dane
Ludzie zmieniają pracę, działy się łączą, skrzynki pocztowe stają się nieaktywne, a status zgody zmienia się w czasie. Degradacja danych jest normalna. Błąd operacyjny to traktowanie wczorajszego ważnego rekordu jako dzisiejszego bezpiecznego rekordu.
Dla zespołów zajmujących się e-mailem, te problemy często zbiegają się na jednej liście. Jeden plik może zawierać porzucone skrzynki pocztowe, konta roli, domeny catch-all, duplikaty i błędy formatowania jednocześnie. Praktyczne wyjaśnienie czyszczenia listy dla wydajności e-maila pomaga wyjaśnić, dlaczego „usuń kilka złych kontaktów" jest zbyt wąskim poglądem na problem.
Czyszczenie również bywa mylone z gromadzeniem. Są to różne zadania. Dodanie większej liczby rekordów do zepsutego systemu zwykle zwiększa ilość błędów, ponieważ te same słabe reguły walidacji, standardy pół i problemy synchronizacji wciąż produkują nowe złe wpisy.
Proces sam w sobie jest dobrze ustanowiony. Przegląd techniczny w odnośniku przepływu pracy czyszczenia danych opisuje podstawowe kroki, takie jak usuwanie duplikatów, obsługa brakujących wartości, standaryzacja formatów, walidacja kompletności i sprawdzenie dokładności przed analizą lub aktywacją. Ta praca znajduje się powyżej jakości raportowania, automatyzacji i modeli.
Zasada „garbage in, garbage out" jest dosłownym opisem tego, co dzieje się w operacjach. Raporty odzwierciedlają złe dane wejściowe. Automatyzacje uruchamiają się na niewłaściwych warunkach. Modele uczą się z rekordów, które nigdy nie powinny dotrzeć do systemów produkcyjnych.
Wymierny koszt degradacji danych
Słaba jakość danych kosztuje organizacje średnio 12,9 miliona dolarów rocznie, według IBM. Ta liczba przyciąga uwagę, ale uszkodzenie operacyjne jest łatwiejsze do przeoczenia, ponieważ pojawia się w dziesiątkach pozycji: zmarnowane wydatki na media, niższe współczynniki konwersji, złe prognozy i doświadczenia klientów, które wydają się niedbałe zamiast skoordynowane (IBM via Experian).
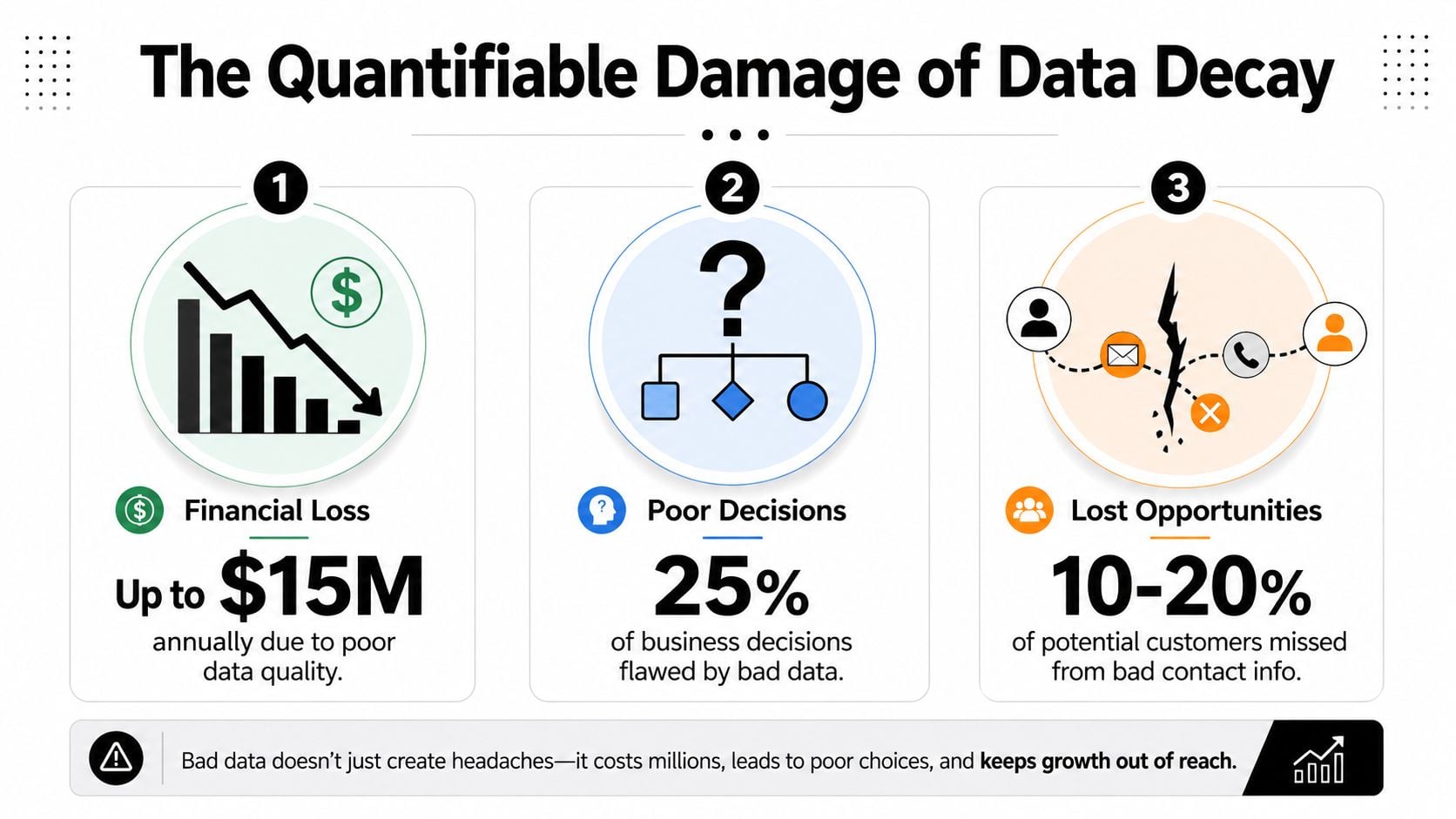
Małe problemy z listami stają się dużymi wyciekami finansowymi
Email szybko uwidacznia koszty. Jeśli 10% z listy 100 000 kontaktów jest nieprawidłowych, a mimo to płacisz za pozyskanie lub wysłanie wiadomości do tych kontaktów, budżet zostaje już spalony zanim kampania ma szansę na wykonanie. Następnie pojawia się koszt drugiego rzędu. Wyższe współczynniki odbicia zmniejszają umiejscowienie w skrzynce odbiorczej, co zmniejsza wartość pozostałych prawidłowych adresów.
Dlatego zespoły dostarczalności obserwują współczynnik odbicia jako metrykę zysku, a nie tylko metrykę e-mail. Praktyczne wyjaśnienie dlaczego współczynniki odbicia mają znaczenie dla sukcesu kampanii pokazuje, jak degradacja listy zmienia się w problemy reputacji nadawcy, które wpływają na przyszłe wysyłania, a nie tylko na bieżące.
Widziałem, jak to rozgrywa się w przeglądach kwartalnych. Marketing zgłasza problem kreatywny lub ofertowy. Podstawowy problem to jakość listy. Zespół stale optymalizuje treść, podczas gdy dostawcy skrzynek pocztowych zmniejszają umiejscowienie w skrzynce odbiorczej.
Naprawa zaczyna się od lepszych danych wejściowych. Zespoły, które weryfikują adresy przed uruchomieniem i między kampaniami, mogą zapewnić jakość listy marketingowej i przestać płacić za wysyłanie wiadomości, które nigdy nie były dostarczalne.
Złe rekordy zniekształcają decyzje po zakończeniu kampanii
Większy koszt często pojawia się po wysłaniu. Zanieczyszczone dane psują atrybucję, definicje odbiorców i raportowanie wydajności. Jeśli zduplikowane rekordy dzielą historię zaangażowania na dwa profile, jeden klient może wyglądać jak dwa słabe leady zamiast jednego wykwalifikowanego nabywcy. Jeśli etap cyklu życia lub status zgody jest przestarzały, zła publiczność jest liczona w złej kohorcie. To zmienia decyzje dotyczące budżetu.
Gartner oszacował, że słaba jakość danych kosztuje organizacje średnio 12,9 miliona dolarów rocznie, a ta liczba pomaga wyjaśnić, dlaczego złe rekordy powodują więcej niż tylko techniczne prace czyszczące. Powodują one błędy finansowe na poziomie zarządzania, ponieważ zespoły przydzielają wydatki, siłę roboczą i kombinację kanałów na podstawie raportów, którym nie powinni ufać (Gartner, cited here).
Doświadczenie klienta również traci. Twilio Segment stwierdził, że 56% konsumentów stanie się klientami powtórzeniowymi po spersonalizowanym doświadczeniu, co oznacza, że niedokładna personalizacja niesie bezpośrednią karę przychodową, gdy dane są złe (raport Twilio Segment dotyczący personalizacji). Zduplikowane kontakty, przestarzałe preferencje i niepoprawne identyfikatory prowadzą do powtarzanych wiadomości, nieistotnych rekomendacji i oczywistych błędów CRM, które sygnalizują, że marka nie zwraca uwagi.
Oto wzór biznesowy:
| Problem operacyjny | Efekt bezpośredni | Konsekwencja biznesowa |
|---|---|---|
| Nieprawidłowe adresy e-mail | Wyższe odbicia | Zmarnowany budżet wysyłania i niższe umiejscowienie w skrzynce odbiorczej |
| Zduplikowane kontakty | Podzielone historie i powtórzone działania | Słabe doświadczenie klienta i zawodna atrybucja |
| Niepoprawne pola CRM | Błędna segmentacja | Kampanie kierowane do złej grupy i utracone możliwości konwersji |
| Przestarzała zgoda lub status klienta | Wiadomości do złej publiczności | Ekspozycja zgodności i uszkodzenie marki |
Kilka złych rekordów nie pozostaje małych. Rozprzestrzeniają się przez raportowanie, automatyzację, kierowanie i punkty kontaktu klienta, aż problem higieny danych staje się problemem przychodów.
Praktyczne ramy pracy do czyszczenia danych
Gdy zespoły zaakceptują, że jakość danych wpływa na przychód, kolejnym problemem jest priorytetyzacja. Większość baz danych zawiera zbyt wiele problemów, aby naprawić je wszystkie naraz. Właściwe rozwiązanie to nie dążenie do idealnych danych. To naprawa rekordów, które mają największy operacyjny zasięg oddziaływania.
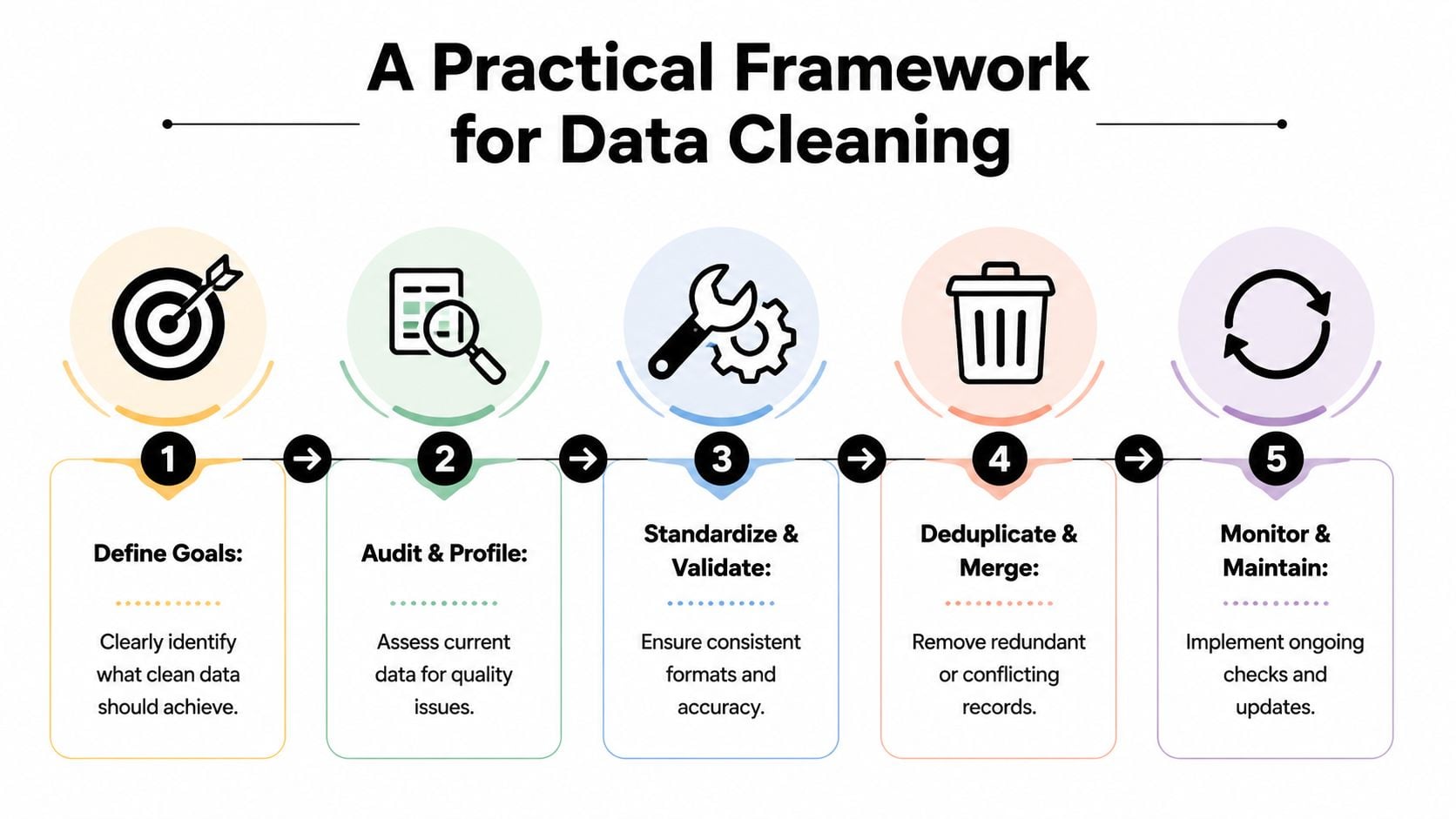
Zacznij od wpływu na biznes, a nie doskonałości danych
Przydatna sekwencja wygląda następująco:
Zdefiniuj wynik biznesowy
Zdecyduj, co czyste dane muszą chronić lub poprawiać. W marketingu może to być dostarczalność, dokładność segmentacji lub niezawodność przypisania. W sprzedaży może to być wydajność routingu i sekwencji.Oceń obecny stan
Przeprowadź audyt bazy danych pod kątem duplikatów, brakujących wartości, niespójnych formatów, nieprawidłowych e-maili i nieaktualnych rekordów. Ten krok powinien wytworzyć kategorie awarii, a nie tylko długą listę błędów.Standaryzuj to, co nigdy nie powinno się zmieniać
Znormalizuj pola takie jak imiona i nazwiska, kraje, stany, formaty numerów telefonów, etapy cyklu życia i wartości źródła. Standaryzacja eliminuje niejasności, zanim spróbujesz analizować lub automatyzować.Usuń duplikaty i scalaj ostrożnie
Nie po prostu usuwaj podejrzane duplikaty. Zdecyduj, który rekord jest systemem rejestrowania i jak powinny być scalane historia zaangażowania, własności i zgody.Sprawdzaj poprawność pól wysokiego ryzyka przed użyciem
Pola skierowane do klientów zasługują na ściślejszą weryfikację niż metadane o niskim wpływie. Adresy e-mail, wskaźniki zgody i pola personalizacji powinny być sprawdzane przed wyzwoleniem kampanii.
To jest również miejsce, gdzie narzędzia wkraczają do rozmowy. W przypadku zespołów skupionych specjalnie na danych kontaktowych, BillionVerify to profesjonalna usługa weryfikacji poczty elektronicznej zbudowana, aby rozwiązać jeden problem: zła jakość danych e-mail kosztuje przedsiębiorstwa pieniądze.
Użyj prostego modelu priorytetyzacji
Macierz wpływ-kontra-wysiłek utrzymuje pracę praktyczną.
Wysoki wpływ, mały wysiłek
Walidacja e-mail, tłumienie duplikatów i normalizacja formatowania zwykle należą tutaj. Te poprawki często szybko poprawiają wydajność kampanii.Wysoki wpływ, duży wysiłek
Rozwiązanie tożsamości cross-systemowej i zarządzanie polami CRM pasują do tej kategorii. Warto je robić, ale wymagają one własności i dyscypliny procesowej.Mały wpływ, mały wysiłek
Czyszczenie kosmetyczne i porządkowanie etykiet pól mogą nastąpić później, chyba że blokują raportowanie.Mały wpływ, duży wysiłek
Unikaj ich na wczesnym etapie. Zespoły często tracą czas na czyszczenie niejasnych starszych pól, które nie wpływają na działalność przychodową.
Wiele zespołów marketingowych popełnia błąd, zaczynając od szerokich czyszczenia CRM, gdy powinni zacząć od rekordów aktywnie używanych w kampaniach. Jeśli plik e-mail jest brudny, nic innego nie dostaje uczciwego testu. To jeden powód, dla którego praktyczne wskazówki dotyczące utrzymania listy, takie jak co czyszczenie listy oznacza dla wydajności poczty elektronicznej, jest takie przydatne w planowaniu operacyjnym.
Zbuduj kontrole, zanim kolejne przesłanie znowu coś zepsuje
Czyszczenie bez kontroli tworzy pętlę pracy. Baza danych wygląda lepiej przez tydzień, a następnie kolejny import, formularz, synchronizacja lub ręczna aktualizacja ponownie wprowadza te same wady.
Używaj kontroli, takich jak:
- Walidacja wpisów dla formularzy i importów
- Reguły pól dla standardowych wartości
- Logika przeglądu duplikatów przed utworzeniem rekordu
- Reguły własności dla tego, kto może edytować pola wrażliwe
- Zaplanowane audyty dla aktywnych list kampanii
Celem nie jest jednorazowe czyszczenie. To zmniejszenie przyszłego zanieczyszczenia.
Rozwiązanie problemu danych e-mail dzięki weryfikacji
E-mail zasługuje na osobne potraktowanie, ponieważ jedno błędne pole może spowodować natychmiastową stratę finansową. Błędnie napisane stanowisko może zniekształcić raportowanie. Nieprawidłowy lub ryzykowny adres e-mail marnuje wolumen wysyłania, zwiększa koszt pozyskania, pogarsza dostarczalność i zniekształca wyniki kampanii na tyle, że zespoły podejmują błędne decyzje budżetowe.
Dlaczego e-mail wymaga specjalistycznej weryfikacji
Sprawdzenia formatu łapią tylko oczywiste błędy. Nie potwierdzają, czy skrzynka pocztowa może odbierać pocztę, czy adres należy do dostawcy adresów jednorazowych, czy wysłanie do niego stwarza ryzyko reputacyjne.
To rozróżnienie ma znaczenie w programach przychodowych. Jeśli płatny formularz leadów akceptuje fałszywe lub tymczasowe adresy, problem nie pozostaje w bazie danych. Marketing płaci za pozyskanie bezużytecznych rekordów, dział sprzedaży kontaktuje się z martwymi kontaktami, a raportowanie kampanii przesadnia rozmiar listy, a zaniża prawdziwą stopę konwersji. Widziałem wiele zespołów, które obwiniały kreatywność, ofertę i timing, gdy podstawowym problemem było to, że zbyt duża część pliku nigdy nie powinna była być wysłana.
Narzędzie weryfikacyjne takie jak BillionVerify wypełnia tę lukę, sprawdzając sygnały dostarczalności w czasie rzeczywistym i oznaczając adresy wyższego ryzyka, zanim wpłyną na wydajność. Jeśli porównujesz podejścia u różnych dostawców i w różnych procesach, warto przejrzeć, jak inne zespoły zapewniają jakość listy marketingowej przed podjęciem decyzji, jaki poziom weryfikacji potrzebujesz.
Gdzie weryfikacja wpasowuje się w przepływ pracy
Weryfikacja przynosi największy zwrot na trzech etapach operacyjnych:
W punkcie wejścia
Zweryfikuj adresy podczas rejestracji, przechwytywania leadów i przesyłania formularzy, aby złe rekordy nie trafiały do CRM od samego początku.Przed głównymi kampaniami
Zweryfikuj aktywną listę wysyłania przed uruchomieniami produktów, promocjami i wysyłkami ponownego zaangażowania. Zespoły zwykle najszybciej odzyskują zmarnowany wolumen podczas tej czynności.Zgodnie z powtarzającym się harmonogramem czyszczenia
Dane e-mail degradują się z czasem. Weryfikacja powinna być częścią rutynowej konserwacji listy, aby plik nie powrócił do tego samego wzoru awarii.
Zespoły, które chcą zrozumieć praktyczne mechanizmy, powinny zacząć od jasnego wyjaśnienia, jak weryfikacja e-mail działa w praktyce. Po wyjaśnieniu procesu znacznie łatwiej jest umieścić weryfikację w formularzach, synchronizacjach CRM i sprawdzeniach przed wysłaniem bez spowalniania wykonania.
Mierzenie zwrotu z inwestycji w czystość danych
Zła jakość danych kosztuje organizacje średnio 12,9 miliona dolarów rocznie, zgodnie z raportem Gartner. Dlatego rozmowy o ROI wokół czyszczenia danych przebiegają lepiej, gdy zaczynają się od aspektów finansowych, a nie technicznych.
Prosty model jest wystarczający, aby rozpocząć poważną dyskusję:
ROI = (Uzyskana wartość + Uniknięte koszty) / Koszt inwestycji
Używam tej struktury, ponieważ odzwierciedla ona, jak zła jakość danych wpływa na rachunek zysków i strat marketingu. Niektóre straty pojawiają się jako utracony przychód. Inne to zmarnowane budżety, ręczne prace naprawcze, ryzyko compliance i wolniejsze podejmowanie decyzji.
Praktyczny sposób na opracowanie uzasadnienia biznesowego
Zacznij od pozycji, które kierownik marketingu już posiada lub na które może wpływać:
- Zmarnowane budżety kampanii na wysyłanie do kontaktów, które nigdy się nie przeliczą
- Utracony przychód z powodu gorszej dostarczalności, słabego targetowania lub zepsutej personalizacji
- Godziny pracy operacyjne i analityków spędzane na naprawie zapobiegalnych błędów pól, duplikatów i złych połączeń
- Ryzyko compliance związane ze słabymi zapisami zgody i niespójną higieną CRM
- Koszty marki i zaufania klientów gdy zła osoba otrzymuje złą wiadomość więcej niż raz
Błąd, który widzę w żądaniach budżetowych, to fakt, że zespoły liczą tylko zyski. Liderzy finansów chcą również zobaczyć, co firma przestaje tracić. Obejmuje to ekspozycję powstałą w wyniku słabych kontroli retencji, niedokładnego statusu zgody i niekompletnych historii kontaktów. Jak wspomniano wcześniej, problemy z jakością danych nie pozostają w zespole operacyjnym. Wpływają na efektywność kampanii, wiarygodność raportów i gotowość do audytu w tym samym czasie.
Z perspektywy uzasadnienia biznesowego: pozycjonuj czyszczenie danych jako inicjatywę ochrony przychodów i poprawy marż. To podejście zwykle uzyskuje szybsze zainteresowanie niż ogólny argument jakości.
Oddziel zyski od unikniętych strat
Najbardziej czyste modele ROI wykorzystują dwie kategorie.
Uzyskana wartość obejmuje mierzalne ulepszenia wydajności: więcej wiadomości docierających do prawdziwych odbiorców, lepszą konwersję z czystszych segmentów odbiorców i raportowanie, któremu możesz ufać przy przesuwaniu wydatków między kanałami lub kampaniami.
Uniknięte koszty obejmują straty, które znikają: mniej zmarnowanych wysyłek, mniej godzin spędzonych na ręcznej naprawie rekordów, mniejsze ryzyko zapobiegalnych problemów compliance i mniejsze uszkodzenia reputacji nadawcy, które mogą obniżyć przyszłą wydajność kampanii.
Utrzymuj szacunek oparty na przepływach pracy, które kontroluje Twój zespół. Jeśli email jest kanałem danych klientów o największym wolumenie, zacznij tam. Zespół marketingu nie potrzebuje modelu danych głównych na poziomie całej firmy, aby uzasadnić działania. Potrzebuje wiarygodnego szacunku odzyskanych wydatków, chronionego przychodu i zmniejszonych prac naprawczych. Dla zespołów budujących ten model ten przewodnik na temat obliczania ROI weryfikacji e-mail zapewnia przydatną strukturę planowania.
Od jednorazowej poprawy do proaktywnej strategii danych
Firmy, które dobrze zarządzają danymi, nie czekają na problem z pulpitem nawigacyjnym lub incydent związany z dostarczalnością. Budują rutyny, które uniemożliwiają złym rekordom wejście do krytycznych systemów od samego początku.
Zwykle oznacza to, że trzy nawyki stają się standardowe. Po pierwsze, sprawdzaj dane w punkcie przechwytywania, szczególnie w formularzach skierowanych do klientów i listach kampanii. Po drugie, przeprowadzaj cykliczne audyty rekordów zasilających aktywne działania outreach i raporty. Po trzecie, zdefiniuj właściwość, aby ludzie wiedzieli, kto może zmieniać pola, scalać rekordy i zatwierdzać importy.
Następuje tu również zmiana podejścia strategicznego. Czyste dane nie są stanem końcowym. To dyscyplina konserwacyjna. Rekordy się zmieniają, kontakty odpływają, adresy email wygasają, a przekazania między platformami tworzą nowe niespójności. Zespoły traktujące czyszczenie jako projekt jednorazowy w końcu płacą dwukrotnie za te same błędy.
Czyste systemy nie pozostają czyste przypadkowo. Ktoś ustala zasady, ktoś monitoruje wyjątki, a ktoś naprawia przyczyny źródłowe zamiast wielokrotnie czyścić objawy.
Dla liderów marketingu ta dyscyplina staje się przewagą konkurencyjną. Kampanie uruchamiają się z mniejszymi niespodziankami. Raportowanie staje się bardziej wiarygodne. Sprzedaż spędza mniej czasu na kwestionowaniu jakości leadów. Przeglądy zgodności stają się mniej bolesne. A wydajność e-maila bardziej dokładnie odzwierciedla strategię, ponieważ lista nie pracuje przeciwko kampanii.
Jeśli dane e-mail stanowią jedno z największych źródeł marnowania w Twoim funelu, BillionVerify warto ocenić jako część szerszego programu higieny. To spełnia praktyczne potrzeby wielu organizacji: weryfikuj adresy przed wysłaniem, wyłap jednorazowe i ryzykowne wpisy wcześnie i zmniejsz obciążenie operacyjne, które tworzą złe dane e-mail.