


La scarsa qualità dei dati può consumare una quota significativa di ricavi. IBM riferisce che la scarsa qualità dei dati costa all'economia statunitense $3,1 trilioni all'anno (stima IBM sul costo dei dati scadenti). Per un direttore marketing, questo non è un problema astratto di governance dei dati. Si manifesta come media a pagamento inviati a contatti non validi, tempo di vendita sprecato su lead scadenti, segmentazione più debole e rapporti di attribuzione che fanno sembrare rotte le campagne sane.
Ho visto lo stesso modello nei team di generazione della domanda. Un elenco può sembrare abbastanza grande da raggiungere gli obiettivi della pipeline nascondendo record duplicati, email obsolete e errori di formattazione che riducono i tassi di risposta e aumentano i costi di acquisizione. L'email è solitamente il posto più veloce per vedere la perdita, motivo per cui liste email pulite contano per le prestazioni della campagna e la reputazione del mittente.
La domanda aziendale è semplice. Qual è il costo di mantenere record scadenti per un altro trimestre?
Quel costo si trova in due posti. In primo luogo, c'è uno spreco diretto: invii extra, costi di piattaforma più elevati, conversione più bassa da campagne mal mirate e ore SDR spese su record che non avrebbero mai dovuto entrare nel sistema. In secondo luogo, c'è danno a cascata al processo decisionale. Se l'origine del lead, i campi firmografici o la cronologia dell'engagement sono errati, il team finanzia i canali sbagliati e taglia quelli giusti. Ecco perché i programmi di dati forti iniziano con l'impatto aziendale, non con la perfezione del database, un punto rafforzato da approfondimenti sulla qualità dei dati di Orbit AI.
La pulizia dei dati guadagna budget quando i team la trattano come protezione dei ricavi con ROI misurabile, non come manutenzione di routine.
La pulizia dei dati è una strategia di ricavi, non un compito IT
Molte organizzazioni ancora parlano della pulizia dei dati come se fosse un lavoro amministrativo. È un errore. Quando i team di ricavi inviano messaggi a contatti non validi, personalizzano da record corrotti, o segmentano su campi obsoleti, non stanno affrontando un fastidio tecnico. Stanno finanziando scarso rendimento.
Il motivo per cui la pulizia dei dati è importante ha meno a che fare con database ordinati e più a che fare con la qualità dell'esecuzione. Il marketing può produrre creatività forte, offerte intelligenti e pianificazione disciplinata delle campagne, poi perdere performance perché il file del pubblico è sbagliato al momento dell'invio. Le vendite possono lavorare un territorio promettente, poi scoprire che il CRM è pieno di duplicati, ruoli obsoleti e indirizzi email non validi. I team di prodotto possono studiare il comportamento di registrazione, poi addestrare decisioni su input difettosi.
Molto del pensiero operativo più forte in quest'area ora tratta l'igiene dei dati come un sistema aziendale, non come una pulizia una tantum. La cornice in Insight sulla qualità dei dati di Orbit AI è utile perché collega la qualità dei dati all'affidabilità operativa piuttosto che trattarla come un compito di database isolato.
Regola pratica: Se un campo influenza il targeting, la personalizzazione, il routing o il reporting, non è un campo IT. È un campo di ricavi.
Quel cambiamento di mentalità è importante perché i dati di contatto difettosi tendono a nascondersi dietro le metriche del canale. I team incolpano le righe dell'oggetto, la qualità dell'offerta, o la velocità di follow-up delle vendite quando la lista stessa è il problema. Nei programmi di email in particolare, la qualità della lista determina se la campagna ha anche una possibilità equa. Ecco perché molti team iniziano a rafforzare l'igiene della lista e a esaminare risorse come perché le liste di email pulite sono importanti prima di cambiare strategia altrove.
L'anatomia dei dati sporchi
I dati sporchi creano rischi operativi molto prima che qualcuno li etichetti come un problema di qualità dei dati. In pratica, si manifestano come una campagna a pagamento inviata a caselle di posta non valide, lead instradati al rappresentante sbagliato, contatti duplicati che gonfiano i conteggi della pipeline, o record di consenso che non corrispondono più a ciò che il marketing è autorizzato a inviare.
All'interno di CRM, ESP, moduli di iscrizione, strumenti di arricchimento e piattaforme BI, i record difettosi raramente si annunciano. Sembrano utilizzabili finché un team non prova a segmentare, instradare, personalizzare, segnalare o prevedere da essi. Questo è il motivo per cui i dati sporchi sono costosi. Falliscono nel punto di utilizzo, dopo che budget, tempo e processo decisionale sono già stati impegnati.
I dati sporchi si presentano in cinque forme familiari
Questi sono i modelli di errore che creano la maggior parte dell'attrito operativo:
Record incompleti
I campi mancanti interrompono le regole di segmentazione, il punteggio dei lead, la logica di instradamento e la personalizzazione. Un contatto senza un'email valida, una regione o una fase del ciclo di vita può rimanere nel database per mesi e rimanere comunque inutilizzabile quando la campagna entra in vigore.Voci inesatte
Errori di battitura, input falsi, indirizzi malformati e dettagli firmografici errati creano false sicurezze. Il record esiste, ma il team non può fare affidamento su di esso.Record duplicati
I duplicati dividono la cronologia di engagement, l'attribuzione e la proprietà. Il marketing può sopprimere un record e inviare per posta l'altro. Le vendite possono chiamare lo stesso acquirente due volte. La segnalazione quindi conta l'attività su due profili e rappresenta male le prestazioni.Formattazione incoerente
Lo stesso nome dell'azienda, paese o funzione lavorativa appare in diversi formati. Il filtro diventa inaffidabile, le regole di corrispondenza perdono sovrapposizioni ovvie e i team iniziano a correggere i rapporti manualmente nei fogli di calcolo.Dati obsoleti
Le persone cambiano lavoro, i dipartimenti si fondono, le caselle di posta diventano dormienti e lo stato del consenso cambia nel tempo. Il deterioramento dei dati è normale. L'errore operativo è trattare il record valido di ieri come il record sicuro di oggi.
Per i team di email, questi problemi spesso convergono in un unico elenco. Un singolo file può contenere caselle di posta abbandonate, account di ruolo, domini catch-all, duplicati ed errori di formattazione allo stesso tempo. Una spiegazione pratica di cosa comporta la pulizia degli elenchi per le prestazioni della posta elettronica aiuta a chiarire perché "rimuovere pochi contatti errati" è una visione troppo ristretta del problema.
La pulizia spesso viene confusa con la raccolta. Sono lavori diversi. Aggiungere più record a un sistema rotto solitamente aumenta il volume degli errori, perché le stesse regole di convalida deboli, standard di campo e problemi di sincronizzazione continuano a produrre nuovi record errati.
Il processo stesso è ben consolidato. La panoramica tecnica nel riferimento del flusso di lavoro di pulizia dei dati descrive i passaggi fondamentali come la rimozione di duplicati, la gestione dei valori mancanti, la standardizzazione dei formati, la validazione della completezza e il controllo dell'accuratezza prima dell'analisi o dell'attivazione. Questo lavoro si trova a monte della qualità della segnalazione, della qualità dell'automazione e della qualità del modello.
Il principio dell'immondizia in, immondizia fuori è una descrizione letterale di ciò che accade nelle operazioni. I report riflettono input scadenti. Le automazioni si attivano su condizioni sbagliate. I modelli imparano da record che non avrebbero mai dovuto raggiungere i sistemi di produzione.
Il danno quantificabile della decadenza dei dati
La scarsa qualità dei dati costa alle organizzazioni una media di $12,9 milioni all'anno, secondo IBM. Questo numero attira l'attenzione, ma il danno operativo è più facile da perdere perché si manifesta in decine di voci: spesa pubblicitaria sprecata, tassi di conversione inferiori, previsioni errate ed esperienze clienti che sembrano negligenti invece che coordinate (IBM tramite Experian).
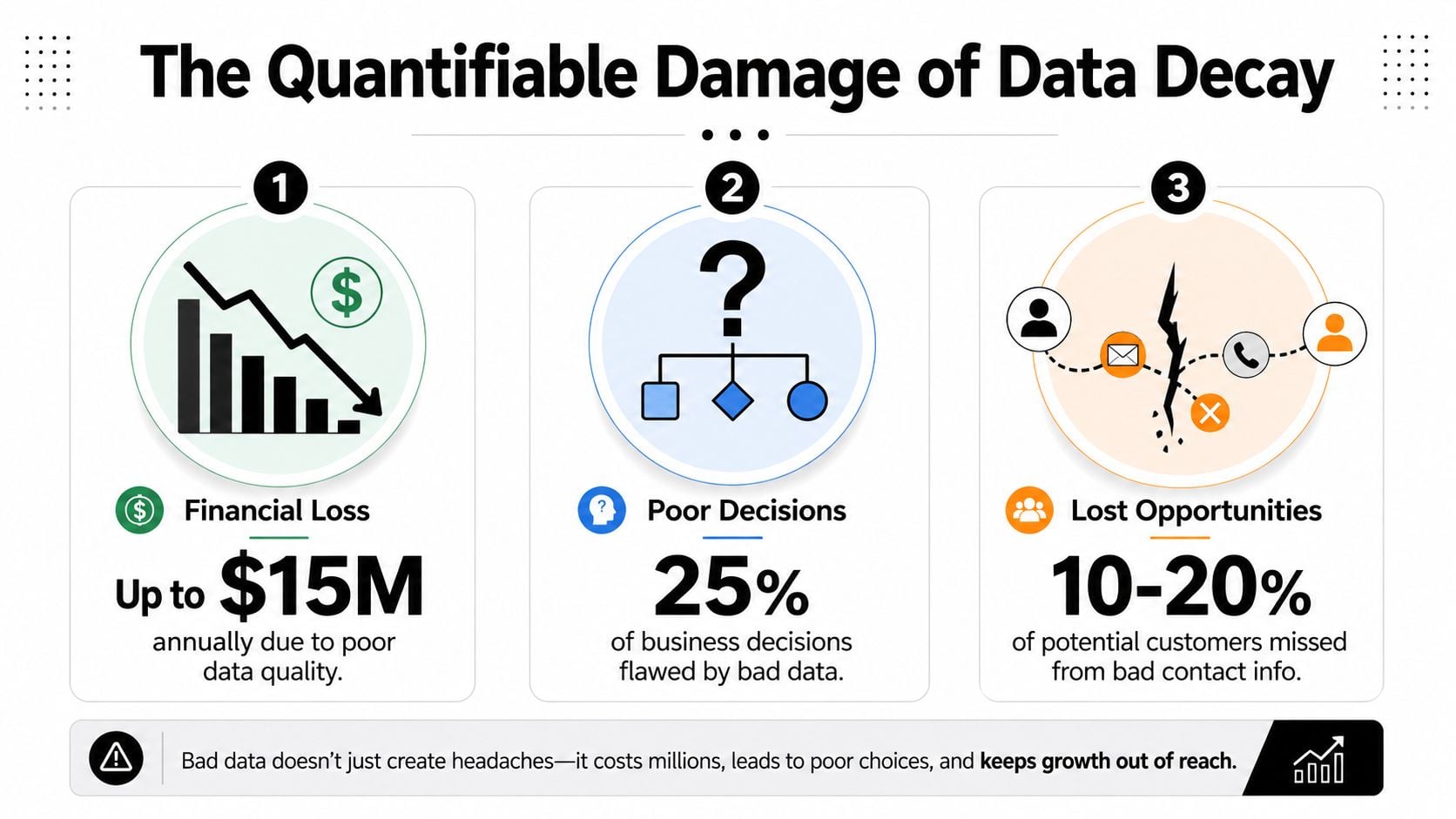
I piccoli problemi di lista diventano perdite finanziarie significative
L'email rende il costo visibile rapidamente. Se il 10% di una lista di 100.000 contatti non è valido e paghi comunque per acquisire o inviare messaggi a quei contatti, il budget è già bruciato prima che la campagna abbia la possibilità di funzionare. Poi arriva il costo di secondo ordine. Tassi di rimbalzo più elevati danneggiano il posizionamento della posta in arrivo, il che riduce il valore degli indirizzi validi che hai ancora.
Ecco perché i team di recapitabilità osservano il tasso di rimbalzo come metrica di profitto, non solo come metrica di posta. Una spiegazione pratica di perché i tassi di rimbalzo sono importanti per il successo della campagna mostra come il decadimento della lista si trasforma in problemi di reputazione del mittente che influenzano gli invii futuri, non solo quello attuale.
L'ho visto accadere nelle revisioni trimestrali. Il marketing riporta un problema creativo o di offerta. Il problema sottostante è la qualità della lista. Il team continua a ottimizzare il testo mentre i provider di caselle postali continuano a ridurre il posizionamento della posta in arrivo.
La soluzione inizia con migliori input. I team che verificano gli indirizzi prima del lancio e tra le campagne possono garantire la qualità della lista di marketing e smettere di pagare per inviare messaggi che non erano mai consegnabili.
I record errati distorcono le decisioni dopo la fine della campagna
Il costo maggiore spesso appare dopo l'invio. I dati sporchi corrompono l'attribuzione, le definizioni del pubblico e i rapporti sulle prestazioni. Se i record duplicati dividono la cronologia di coinvolgimento su due profili, un cliente può sembrare due lead deboli invece di un acquirente qualificato. Se lo stadio del ciclo di vita o lo stato del consenso è obsoleto, il pubblico sbagliato viene conteggiato nella coorte sbagliata. Questo cambia le decisioni di budget.
Gartner ha stimato che la scarsa qualità dei dati costa alle organizzazioni una media di $12,9 milioni annualmente, e questa cifra aiuta a spiegare perché i record errati creano più del semplice lavoro di pulizia tecnica. Producono errori finanziari a livello gestionale, perché i team allocano la spesa, il numero di dipendenti e il mix di canali in base ai rapporti su cui non dovrebbero fidarsi (Gartner, citato qui).
L'esperienza del cliente ne risente anche. Twilio Segment ha scoperto che il 56% dei consumatori diventerà un acquirente abituale dopo un'esperienza personalizzata, il che significa che la personalizzazione imprecisa comporta una penalità diretta sui ricavi quando i dati sottostanti sono errati (Rapporto di personalizzazione Twilio Segment). I contatti duplicati, le preferenze obsolete e gli identificatori non corretti portano a messaggi ripetuti, raccomandazioni irrilevanti e errori CRM ovvi che segnalano che il brand non sta prestando attenzione.
Ecco il modello di business:
| Problema operativo | Effetto immediato | Conseguenza aziendale |
|---|---|---|
| Indirizzi email non validi | Rimbalzi più elevati | Budget di invio sprecato e posizionamento inferiore della posta in arrivo |
| Contatti duplicati | Storie suddivise e contattazione ripetuta | Esperienza cliente scarsa e attribuzione inaffidabile |
| Campi CRM non corretti | Segmentazione difettosa | Campagne mal mirate e opportunità di conversione perse |
| Consenso obsoleto o stato del cliente | Messaggistica al pubblico sbagliato | Esposizione normativa e danno al brand |
Pochi record errati non rimangono piccoli. Si diffondono attraverso rapporti, automazione, targeting e punti di contatto dei clienti finché un problema di igiene dei dati non diventa un problema di ricavi.
Un Quadro Pratico per la Pulizia dei Dati
Una volta che i team accettano che la qualità dei dati influisce sui ricavi, il problema successivo è la prioritizzazione. La maggior parte dei database contiene troppi problemi per ripulirli tutti in una volta. La mossa giusta non è inseguire dati perfetti. È correggere i record che hanno il raggio d'impatto operativo più alto.
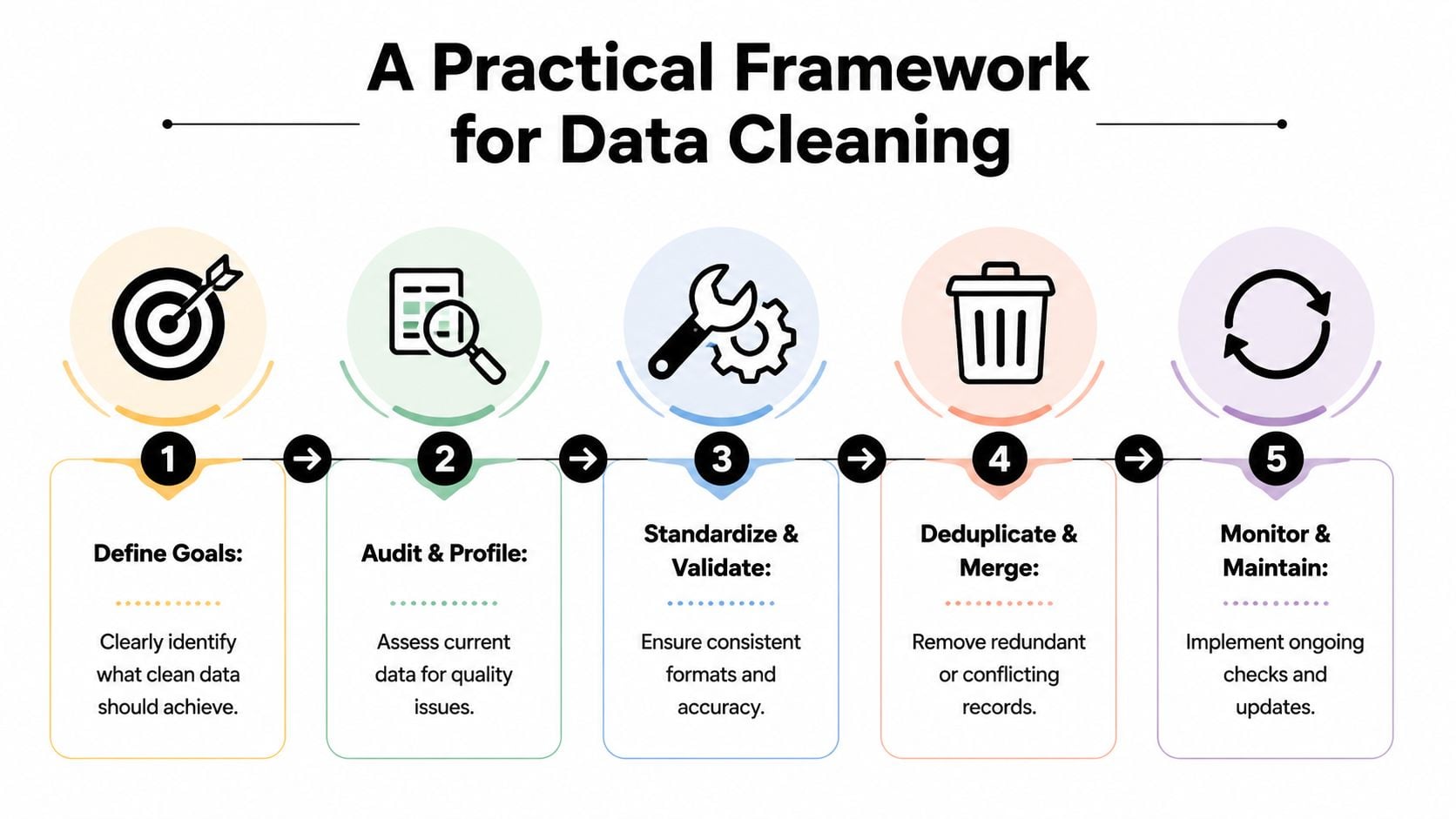
Inizia con l'impatto aziendale, non la perfezione dei dati
Una sequenza utile è la seguente:
Definire il risultato aziendale
Decidi cosa i dati puliti devono proteggere o migliorare. Per il marketing, potrebbe essere la consegna, l'accuratezza della segmentazione o l'affidabilità dell'attribuzione. Per le vendite, potrebbe essere l'efficienza del routing e della sequenza.Profilare lo stato attuale
Controlla il database per duplicati, valori mancanti, formati incoerenti, email non valide e record obsoleti. Questo passaggio dovrebbe produrre categorie di errori, non solo un lungo elenco di errori.Standardizzare quello che non dovrebbe mai variare
Normalizza campi come nomi, paesi, stati, formati di telefono, fasi del ciclo di vita e valori di origine. La standardizzazione rimuove l'ambiguità prima di tentare di analizzare o automatizzare.Deduplicare e unire con cautela
Non eliminare semplicemente i duplicati sospetti. Decidi quale record è il sistema di registrazione e come l'impegno, la proprietà e la cronologia del consenso dovrebbero essere uniti.Convalidare i campi ad alto rischio prima dell'uso
I campi rivolti ai clienti meritano controlli più ristretti rispetto ai metadati a basso impatto. Gli indirizzi email, gli indicatori di consenso e i campi di personalizzazione devono essere convalidati prima di attivare le campagne.
È anche qui che gli strumenti entrano in gioco. Per i team focalizzati specificamente sui dati di contatto, BillionVerify è un servizio professionale di verifica delle email costruito per risolvere un problema: i dati di email errati costano denaro ai business.
Usa un semplice modello di prioritizzazione
Una matrice impatto-versus-sforzo mantiene il lavoro pratico.
Impatto elevato, basso sforzo
La convalida delle email, la soppressione dei duplicati e la normalizzazione della formattazione di solito appartengono qui. Queste correzioni spesso migliorano rapidamente le prestazioni delle campagne.Impatto elevato, sforzo elevato
La risoluzione dell'identità tra sistemi e la governance dei campi CRM si adattano a questa categoria. Valgono la pena di fare, ma richiedono proprietà e disciplina del processo.Impatto basso, basso sforzo
La pulizia cosmetica e l'organizzazione delle etichette dei campi possono avvenire in seguito, a meno che non blocchino il reporting.Impatto basso, sforzo elevato
Evita questi all'inizio. I team spesso bruciano tempo pulendo campi legacy oscuri che non influenzano l'attività di ricavo.
Molti team di operazioni di marketing commettono l'errore di iniziare con un'ampia pulizia CRM quando dovrebbero iniziare con i record attivamente utilizzati nelle campagne. Se il file di email è sporco, nient'altro ottiene un test equo. Ecco un motivo per cui una guida pratica sulla manutenzione dell'elenco come cosa significa la pulizia dell'elenco per le prestazioni delle email è così utile nella pianificazione operativa.
Costruisci controlli prima che il prossimo caricamento rompa di nuovo le cose
La pulizia senza controlli crea un ciclo di rielaborazione. Il database sembra migliore per una settimana, poi l'importazione successiva, il modulo, la sincronizzazione o l'aggiornamento manuale reintroduce gli stessi difetti.
Usa controlli come:
- Convalida di accesso per moduli e importazioni
- Regole di campo per valori standard
- Logica di revisione dei duplicati prima della creazione del record
- Regole di proprietà per chi può modificare i campi sensibili
- Audit programmati per elenchi di campagne attive
L'obiettivo non è una pulizia una tantum. È una minore contaminazione futura.
Risolvere il Problema dei Dati Email con la Verifica
L'email merita un trattamento separato perché un campo errato può creare una perdita finanziaria immediata. Un titolo di lavoro scritto male può distorcere i rapporti. Un indirizzo email non valido o rischioso spreca il volume di invio, aumenta il costo di acquisizione, danneggia la consegnabilità e distorce i risultati della campagna al punto che i team prendono decisioni di budget sbagliate.
Perché l'email ha bisogno di una verifica specializzata
I controlli del formato catturano solo gli errori ovvi. Non confermano se una cassetta postale può ricevere posta, se l'indirizzo appartiene a un fornitore temporaneo, o se l'invio ad esso crea un rischio di reputazione.
Questa distinzione è importante nei programmi di ricavi. Se un modulo di lead a pagamento accetta indirizzi falsi o temporanei, il problema non rimane all'interno del database. Il marketing paga per acquisire record inutilizzabili, le vendite seguono contatti inattivi, e i rapporti della campagna sovrastimano la dimensione dell'elenco mentre sottostimano il vero tasso di conversione. Ho visto team incolpare la creatività, l'offerta e i tempi quando il problema sottostante era che una parte troppo grande del file non avrebbe mai dovuto essere inviata.
Uno strumento di verifica come BillionVerify colma questo divario controllando i segnali di consegnabilità in tempo reale e contrassegnando gli indirizzi a rischio più elevato prima che influiscano sulle prestazioni. Se stai confrontando approcci tra vendor e processi, è utile rivedere come altri team assicurano la qualità dell'elenco di marketing prima di decidere quale livello di verifica hai bisogno.
Dove la verifica si inserisce nel flusso di lavoro
La verifica offre il miglior ritorno in tre punti operativi:
Al punto di ingresso
Convalida gli indirizzi durante l'iscrizione, l'acquisizione di lead e l'invio del modulo in modo che i record errati non entrino nel CRM in primo luogo.Prima di campagne importanti Esamina l'elenco di invio attivo prima dei lanci di prodotti, delle promozioni e degli invii di re-engagement. I team di solito recuperano il volume sprecato più velocemente durante questa attività.
Su un calendario di igiene ricorrente
I dati email si degradano. La verifica dovrebbe rientrare nella manutenzione ordinaria dell'elenco in modo che il file non torni nello stesso modello di errore.
I team che vogliono comprendere la meccanica pratica dovrebbero iniziare con una spiegazione chiara di come funziona la verifica email in pratica. Una volta che il processo è chiaro, diventa molto più facile posizionare la verifica nei moduli, negli syncs CRM e nei controlli pre-invio senza rallentare l'esecuzione.
Misurare il ROI dei Dati Puliti
La scarsa qualità dei dati costa alle organizzazioni una media di $12.9 milioni all'anno, secondo Gartner. Ecco perché le conversazioni intorno al ROI della pulizia dei dati funzionano meglio quando iniziano in termini finanziari, non tecnici.
Un semplice modello è sufficiente per avviare una discussione seria:
ROI = (Valore Ottenuto + Costi Evitati) / Costo dell'Investimento
Utilizzo questa struttura perché riflette come i dati difettosi colpiscono il P&L del marketing. Alcune perdite si manifestano come ricavi mancati. Altre si trovano nella spesa sprecata, nel rework manuale, nel rischio di conformità e nella lentezza del processo decisionale.
Un modo pratico per costruire il business case
Inizia con voci che un direttore marketing già possiede o può influenzare:
- Spesa di campagna sprecata derivante dall'invio a record che non si convertiranno mai
- Ricavi persi da scarsa consegna dei messaggi, scarso targeting o personalizzazione rotta
- Ore di ops e di analisti spese per correggere errori di campo evitabili, duplicati e join errati
- Rischio di conformità legato a deboli record di consenso e igiene CRM incoerente
- Costi di marca e fiducia dei clienti quando la persona sbagliata riceve il messaggio sbagliato, più di una volta
L'errore che vedo nelle richieste di bilancio è che i team contano solo i vantaggi. I leader finanziari vogliono anche vedere cosa l'azienda smette di perdere. Ciò include l'esposizione creata da deboli controlli di retention, da uno stato di consenso inaccurato e da cronologie di contatti incomplete. Come notato in precedenza, i problemi di qualità dei dati non rimangono limitati al team operativo. Influiscono sull'efficienza delle campagne, sulla fiducia nei rapporti e sulla preparazione dell'audit allo stesso tempo.
Prospettiva del business case: Posiziona la pulizia dei dati come un'iniziativa di protezione dei ricavi e miglioramento dei margini. Questo inquadramento solitamente ottiene una trazione più rapida rispetto a un argomento di qualità generico.
Separa il vantaggio dalla perdita evitata
I modelli ROI più puliti utilizzano due categorie.
Valore ottenuto copre il miglioramento delle prestazioni misurabili: più messaggi che raggiungono i destinatari reali, una migliore conversione da segmenti di pubblico più puliti e rapporti su cui puoi fare affidamento quando sposti la spesa tra canali o campagne.
Costi evitati copre le perdite che scompaiono: meno invii sprecati, meno ore spese nella riparazione manuale dei record, meno rischio di problemi di conformità evitabili e meno danno alla reputazione del mittente che può ridurre le prestazioni delle future campagne.
Mantieni la stima radicata nei flussi di lavoro che il tuo team controlla. Se l'email è il flusso di dati dei clienti a volume più elevato, inizia da lì. Un team di marketing non ha bisogno di un modello di dati master a livello aziendale per giustificare l'azione. Ha bisogno di una stima difendibile della spesa recuperata, dei ricavi protetti e del rework ridotto. Per i team che costruiscono quel modello, questa guida al calcolo del ROI della verifica email fornisce una struttura di pianificazione utile.
Da Correzione Singola a Strategia Dati Proattiva
Le aziende che gestiscono bene i dati non aspettano un problema di dashboard o un incidente di deliverability per agire. Creano routine che impediscono l'ingresso di record difettosi nei sistemi critici fin dall'inizio.
Questo di solito significa che tre abitudini diventano standard. Primo, convalida i dati al punto di acquisizione, specialmente per i moduli rivolti ai clienti e gli elenchi di campagne. Secondo, esegui audit ricorrenti sui record che alimentano l'outreach attivo e i report. Terzo, definisci la proprietà in modo che le persone sappiano chi può modificare i campi, unire i record e approvare le importazioni.
C'è anche un cambio di mentalità strategica qui. I dati puliti non sono lo stato finale. È una disciplina di manutenzione. I record cambiano, i contatti si perdono, le caselle di posta scadono e gli scambi tra piattaforme creano nuove incoerenze. I team che trattano la pulizia come un progetto una tantum finiscono per pagare gli stessi errori due volte.
I sistemi puliti non rimangono puliti per caso. Qualcuno stabilisce le regole, qualcuno monitora le eccezioni e qualcuno risolve le cause profonde invece di ripulire ripetutamente i sintomi.
Per i leader del marketing, quella disciplina diventa un vantaggio competitivo. Le campagne si lanciano con meno sorprese. I report diventano più facili da credere. Il team di vendita trascorre meno tempo a dubitare della qualità dei lead. Le revisioni di conformità diventano meno dolorose. E le prestazioni email riflettono la strategia più accuratamente perché l'elenco non ostacola la campagna.
Se i dati email sono una delle più grandi fonti di spreco nel tuo funnel, BillionVerify merita di essere valutato come parte di un programma di igiene più ampio. Soddisfa l'esigenza pratica che molte organizzazioni affrontano: verifica gli indirizzi prima dell'invio, cattura gli indirizzi monouso e rischiosi in anticipo e riduci l'attrito operativo che i dati email difettosi creano.